二手机械硬盘购买
自半年前购入 6 块盘,翻车了一块盘后,记录下买二手机械硬盘的经验。
自半年前购入 6 块盘,翻车了一块盘后,记录下买二手机械硬盘的经验。
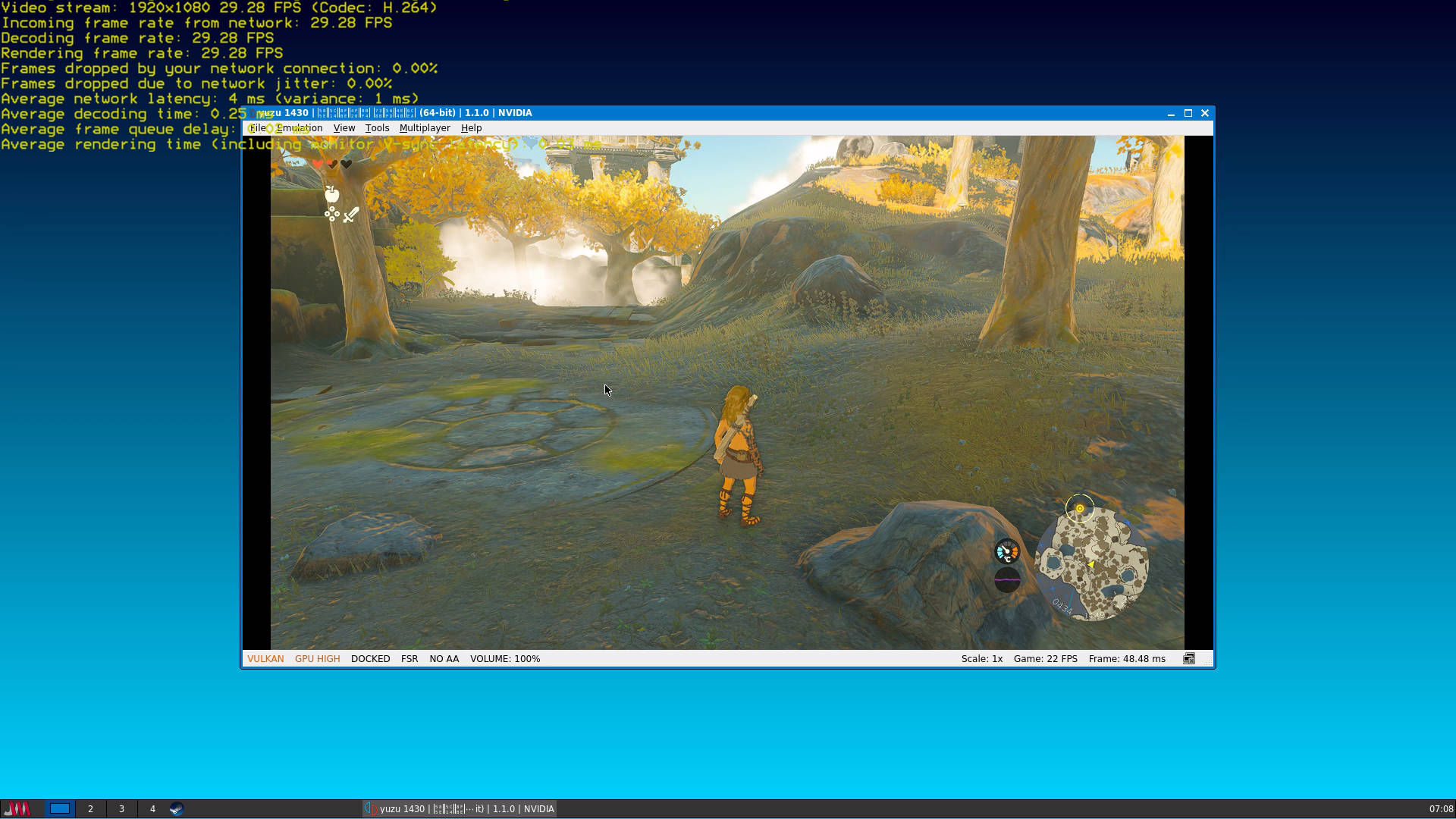
2024 年 10 月 27 日,我终于实现了很久以来的一个心愿——在现实中打一场乒乓球,以此检验我在 VR 里打了 4 个多月球后的水平(我在游戏中目前分数为 1848)。 Eleven Table Tennis
aria2c -c -x 1 -s 2 https://alist.yfycloud.site:4433/d/Guest/Aria2/grpc.tar.xz\?sign\=JzEpqFm02IlJUuYfCQY3RZdU-NxYVyMElvQShef8Wy0\=:0 http://192.168.36.254:
8000/grpc.tar.xz
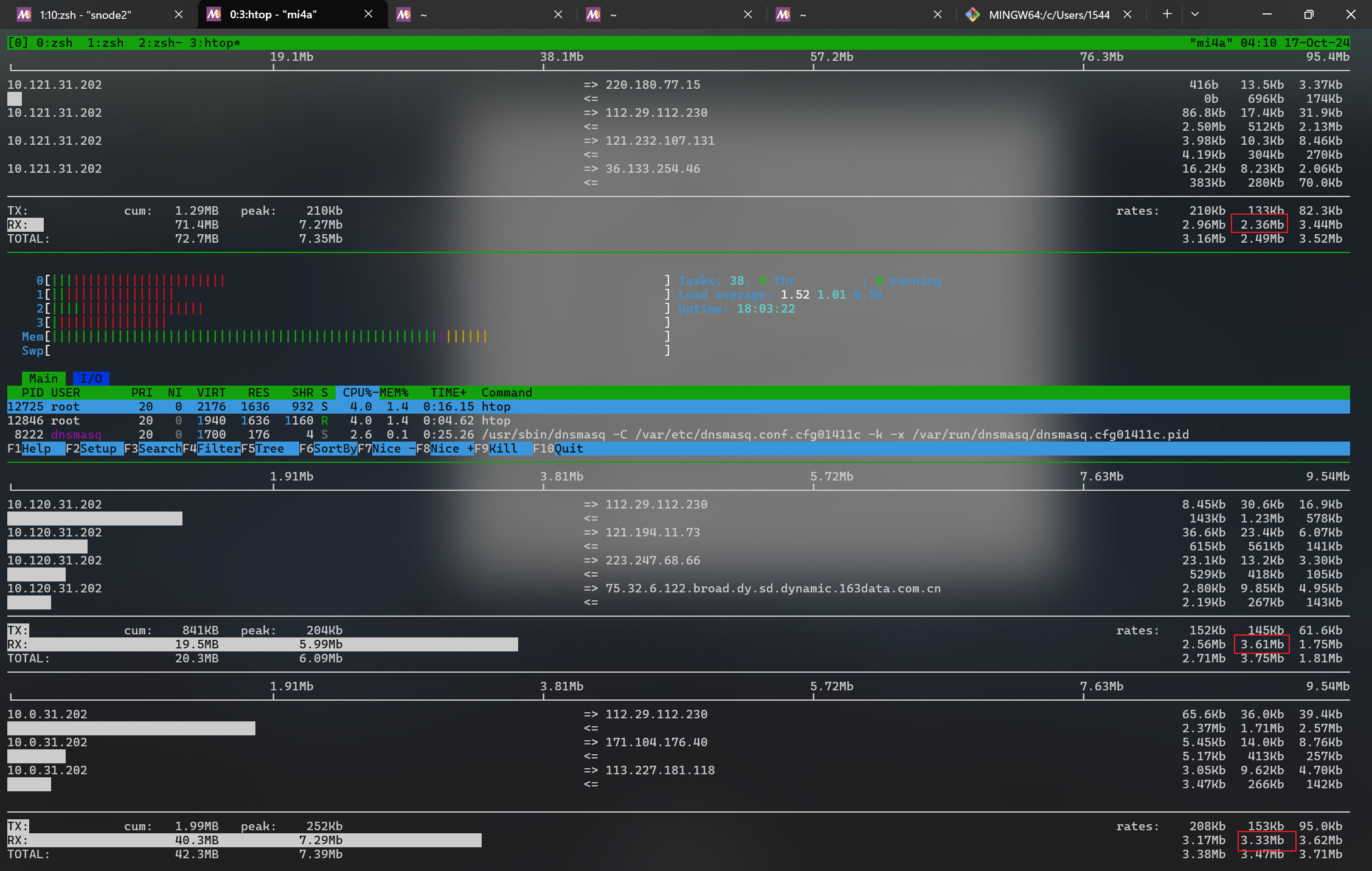
但是上面使用了两台服务器提供相同的文件,由于有两个公网地址(使用 LAN 地址的链接底层 wg 仍然需要一个公网地址),因此分流比较简单。如果要缩减为 1 台服务器,就得有让即使是只有一个公网地址,也可以走不同路由的方法(即分别从以太网和 wifi 出去)
我开始的想法是本地使用一个 nginx 反向代理远程的链接,使得请求不同本地地址 127.0.0.x bind 到不同出口出去。nginx 支持 proxy_bind 参数,支持绑定到不同源 ip 地址。但是没想到 Windows 的路由非常不灵活,无法实现源地址的路由1
后面我利用一个简单的千兆路由器(xiaomi 4A gigabit version)将多台设备连接起来,并在每台设备上开启 nginx 反代,实现了只有一个公网地址的情况下,对同一个服务器的网速叠加效果。
nginx 的方法虽然有效,但是整个 setup 有点复杂(windows 需要配置 nginx,设置路由表),并且只能针对一个目的地址叠加网速。访问网页其它内容就无法加速了。
之后又去了解了 ECMP 技术,其中 per flow 和 per packet 分流的想法看上去确实很美好。如果可以实现的话,可以真正实现针对任意协议的网速叠加。(单连接在 per flow 情况下还无法提升速度,但是能够对不同单连接负载均衡也足够了)
各方案总结
下载 windows11 镜像,从一小时二十分钟,下降到二十分钟


利用 mi4a + 两台 windows 共 3 个路径进行 ECMP,手机播放 B 站 4K 视频时的效果,CPU 有 %30-40 的占用。
假如入你刚好有两台笔记本,或者笔记本和一个大屏的平板。有什么办法把其中一台计算机的屏幕作为另一台计算机使用呢?
调研后,常见的选择是 spacedesk,效果还可以。不过我使用过程中,即使两台笔记本有线连接到路由器,还是遇到了卡顿的情况。因此在考虑是否有其他选择,要是能够有 sunshine+moonlight 那么顺滑就好了,突然一个想法冒入脑海中——是否能用 sunshine 实现扩展屏幕呢?于是尝试起来。
在第一台笔记本上安装好 sunshine 作为服务端。笔记本 CPU 为 i5 1135g7,轻薄本。由于 intel 的编解码都挺强,外加两台笔记本都是千兆网线连接,所以不太担心性能问题。
第二台笔记本安装好 moonlight,连接。结果发现只串流了第一台笔记本的主屏幕,并且是镜像模式。和所想要的效果不一样。我想要的是新增一个屏幕。怀着这理论上应该是可以做到的想法,搜索了 github 的 issue。结果看到有人讨论能否串流多个显示器。确实,我笔记本连接的另一个 27英寸显示器都无法串流。应该有办法切换吧,我这么想着。
讨论中有人提到 sunshine 默认串流主屏幕,可以运行多个 sunshine instance,每个设置串流不同屏幕。这令我突然想到,岂不是可以在第一台笔记本上安装一个虚拟屏幕,第二台笔记本串流这个虚拟屏幕就可以达到扩展的效果了?
结果非常 Amazing 啊,居然真的就 work 了,效果非常丝滑。甚至我觉得比 spacedesk 的效果还要好,毕竟画面的码率都可以调整。
此文主要记录下这个 usecase,并简单记录配置方法。
起因是给 wolf 的开发者提建议时,涉及到了通过 HE(Hurricane Electric) 提供的 6in4 服务接入 ipv6 网络 。既然给别人介绍了,感觉自己不能没有实操过,因此就尝试在自己的网络连入 HE。
I want to streaming over ipv6 network. However wolf only listen on ipv4 for now.
ABeltramo — 2024/10/06 23:42
Probably not, I don't have IPv6 in my LAN/WAN so not sure how to implement it.. Might be worth opening up an issue in Github!
TheRainstorm — 2024/10/06 23:49
Doesn't your ISP provide IPv6? Otherwise, enabling IPv6 should only require enabling it on the home router.
ABeltramo — 昨天00:59
Nope, no IPv6 over here..
TheRainstorm — 昨天14:56
If you want to try out IPv6, there's another way to get the full IPv6 experience, which is through a 6in4 tunnel. Some free services, like Hurricane Electric, allow you to connect to the IPv6 network. However, this requires you to have a public IPv4 address and a router that supports 6in4 functionality (if you're using open-source router firmware like OpenWRT, it is supported by default).
I can provide you with some useful links:
https://www.youtube.com/watch?v=LJPXz8eA3b8&t=64s
https://openwrt.org/docs/guide-user/network/ipv6/ipv6tunnel-luci
ABeltramo — 昨天15:02
Thanks, that's probably my best bet on trying IPv6. I have a WAN IPv4 IP and I use OPNSense in my custom router so it should be possible.
I'm working on a few other bits at the moment, not sure when I'll have the time to look properly into this
接着意识到到,既然我可以 6in4 到国外,岂不是可以直接访问国外 v6 网站?不过由于只有 v6 地址,因此只能访问纯 ipv6 网站。于是我就好奇,在 2024 年纯 ipv6 的体验是怎么样的,因此就有了这篇博客。
秀下最后大大的 No IPv4 address detected
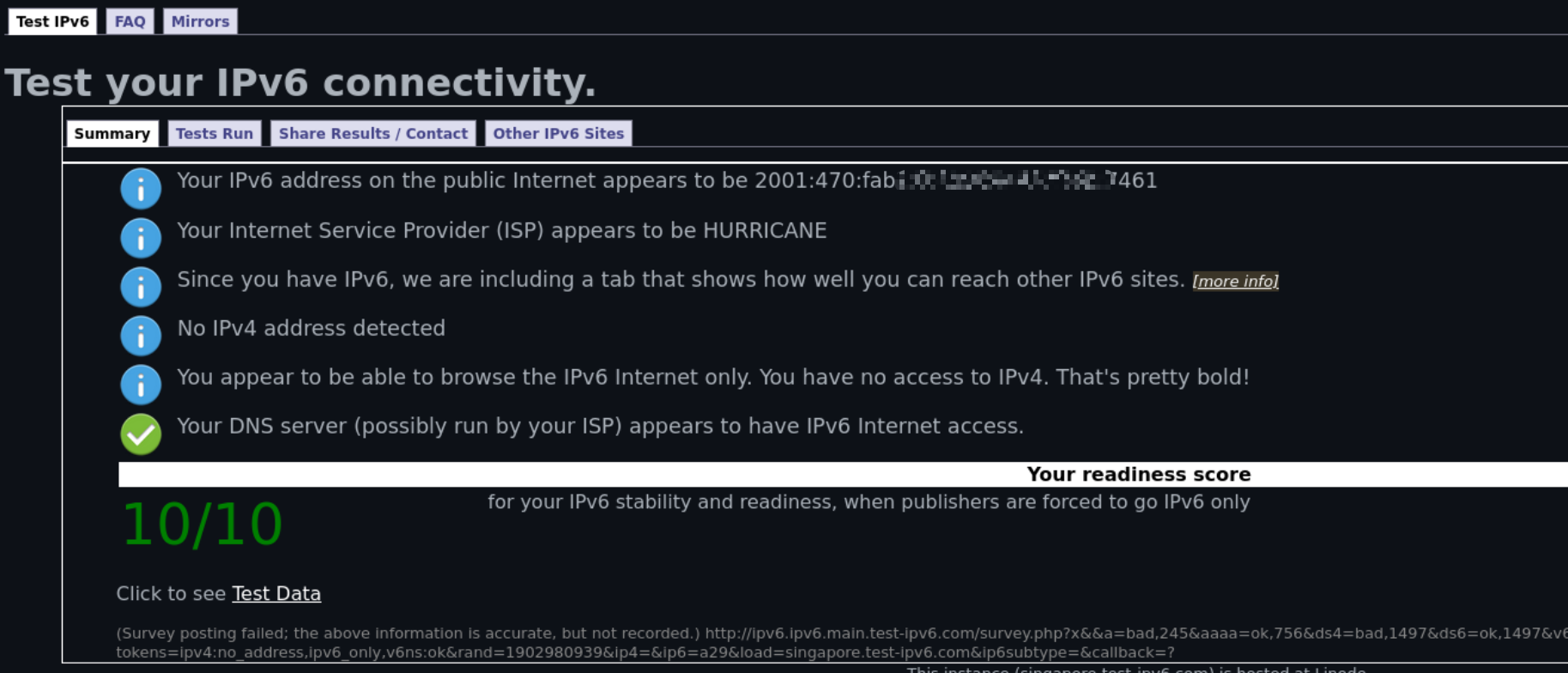
并且 /48 的前缀,我可以划分 65536 个子网!
我自己的机器配置了透明代理,因此配置开发环境等非常方便。但是实验室服务器等其它机器则通常没有自由的网络环境。因此如果能够让其它机器通过我内网的一台 linux 机器(通常是 VM)上网就很方便了。
由于并不需要绕过 GFW,传统的代理协议如 HTTP 代理和 Socks 即可,并且许多软件都对这两种协议有支持。比如 linux 命令行下的软件大部分支持通过环境变量启用代理,如 curl, wget, git。浏览器甚至 windows 操作系统自身通常也支持设置系统代理(也是对浏览器生效)。因此本片文章主要总结了搭建这两种代理服务器的常见软件。
总结:调研下来,虽然这两种协议历史悠久,有成熟的软件工具。但是目前大部分软件功能都太多了,这导致配置很复杂(比如 squid 9000 行的配置文件)这对简单使用代理功能有点 overkill 了。不过虽然配置复杂,学习后至少能用,因此就先不纠结了。**要我说感觉可以使用 python 简单糊一个单文件脚本,支持 1)密码认证 2)基于 ip 的访问控制 3)并且端口复用,同时支持 http 和 socks。可以放在 TODO list 里。
作为第一次认真观看奥运比赛,觉得有必要记录下我的观看方法。
官方列出了各个国家观看奥运的平台:Where to watch Paris 2024 Olympic Games live (olympics.com)
以中国和日本为例:
各个平台大部分都推出了手机 APP 版本,功能更加丰富,比如咪咕视频支持分屏同时播放 4 条视频流,观看不同的解说。查看比赛项目等也非常方便。
不过我更习惯使用电脑观看,因此主要关注 Web 平台。
VR 比较常见的一个功能便是拿来看看视频,巨大的屏幕以及可以切换的各种拟真场景,都可以带来非常高的沉浸感。而多人观影,则使得这个功能更近一步。在多人观影应用中,玩家可以创建虚拟房间,别人可以加入这个房间观看同一部电影。在虚拟场景中,玩家可以看到对面的虚拟形象做出的各种动作,也可以听到对面带有方位感的立体的声音,让人感觉对方仿佛就在眼前一样。
对我来说,VR 多人观影的最大优点可能是可以突破时间空间的限制,加强人与人之间的连接。毕竟现实中想要和好友特别是异地的好友一起看电影实在太难了,而在 VR 中却可以轻易做到。 我相信,这种加强人与人的链接,必然是 VR 未来发展的很重要的一个方向。(比如在 VRChat 中,玩家能做到的不仅是一起观影,还能一起玩游戏、一起逛图甚至一起陪伴睡觉。确实能瞥见一点元宇宙的影子)
回到正题,由于目前 VR 还处于一个开拓区,许多应用都没有完全明确的形态。针对 VR 多人观影,并没有非常成熟的应用,不同软件侧重的功能不同。以下是我对试过的一些方案的总结
http://something.com/video.mp4)https://youtube.com/watch?v=VIDEOID,原理是使用 yt-dlp 工具解析出视频直链):包含 B 站、youtube、twitch直播等其实从原理上,上面应用可以分为两类。
理论上最方便最强大的肯定是 bigscreen 这种,但是由于串流服务器存储和带宽的高昂成本,免费用户必然会受到许多限制。因此我觉得更实际的还是后者。其实对于观看大部分正规正版资源,pico 视频已经没什么问题(要么观看 Pico 视频自带的资源,要么使用其它软件投屏)。然而因为国内的审查政策,导致很多即使正规的内容国内平台不一定引进,引进了也可能删减。因此 VRChat 更加开放这一点还是不可缺少的。
视频链接又可以分为两类
rtmp://dl.live-send.acg.tv/live-dl),B 站可以对视频进行存储(也就是直播回放功能),同时提供 HLS 访问。观看者使用浏览器通过 HLS 协议从 B 站服务器获取直播内容。以下是它们优缺点的介绍
视频直链
直播链接
最后经过研究,围绕 VRChat 确实有许多方案。最简单的,使用 twitch 直播电脑画面,当然同样会遇到码率限制等问题。所以最好的还是利用自己的上传带宽,因此可以在家宽上搭建一个 HLS 的服务器。绑定域名,提供给外网访问。可以使用 OBS 将电脑屏幕、视频播放器等画面推流到自己的 HLS 服务器上。
很多时候,我们想要出门在外也能方便地连入我们的内网。我最近就遇到了到朋友那玩 VR 结果串流不成功的问题。虽然理论上我可以在那慢慢配置 wireguard 啥的,但是通常一下午并没有这么多时间让我折腾。所以就在想是否可以随身携带一个便携路由器,只需要插上网线,连上 wifi 就能快速接入我的内网呢?这便对路由器提出了一些需求:
2)和4)主要是我设想的组网方案会用到 wireguard,而一些硬件主线还没有支持(比如 360t7 和 wr30u 都是 23 下半年才支持的,我买的时候还没有)。虽然有一些第三方的 openwrt 魔改版固件,比如 QWRT,XWRT 等等。但这些系统有一些我无法接受的点,比如使用闭源 wifi 驱动,这导致无法和主线的 openwrt 组 mesh 和 fast roaming 等。另外 wireguard 需要内核模块,如果第三方固件没有的话,也没法自己安装。
3)和 5)主要是因为 VR 串流对于带宽要求是比较高的,在一些高端硬件情况下,码率设置成 500 mbps 都是可行的。我的硬件一般 60 - 100 Mbps 就够了。由于 wg 需要加解密是需要吃较多 CPU 资源的,mt7981 能够跑到 350-400 Mbps 左右(见cyyself/wg-bench: WireGuard Benchmark using netns and iperf3 (github.com))。而经典的 mt7261 MIPS SoC 则只能跑到 100 Mbps 左右就明显不够用了。因此为了保障有较好体验,wifi 6 和 mt7981 我觉得是个基准线了。
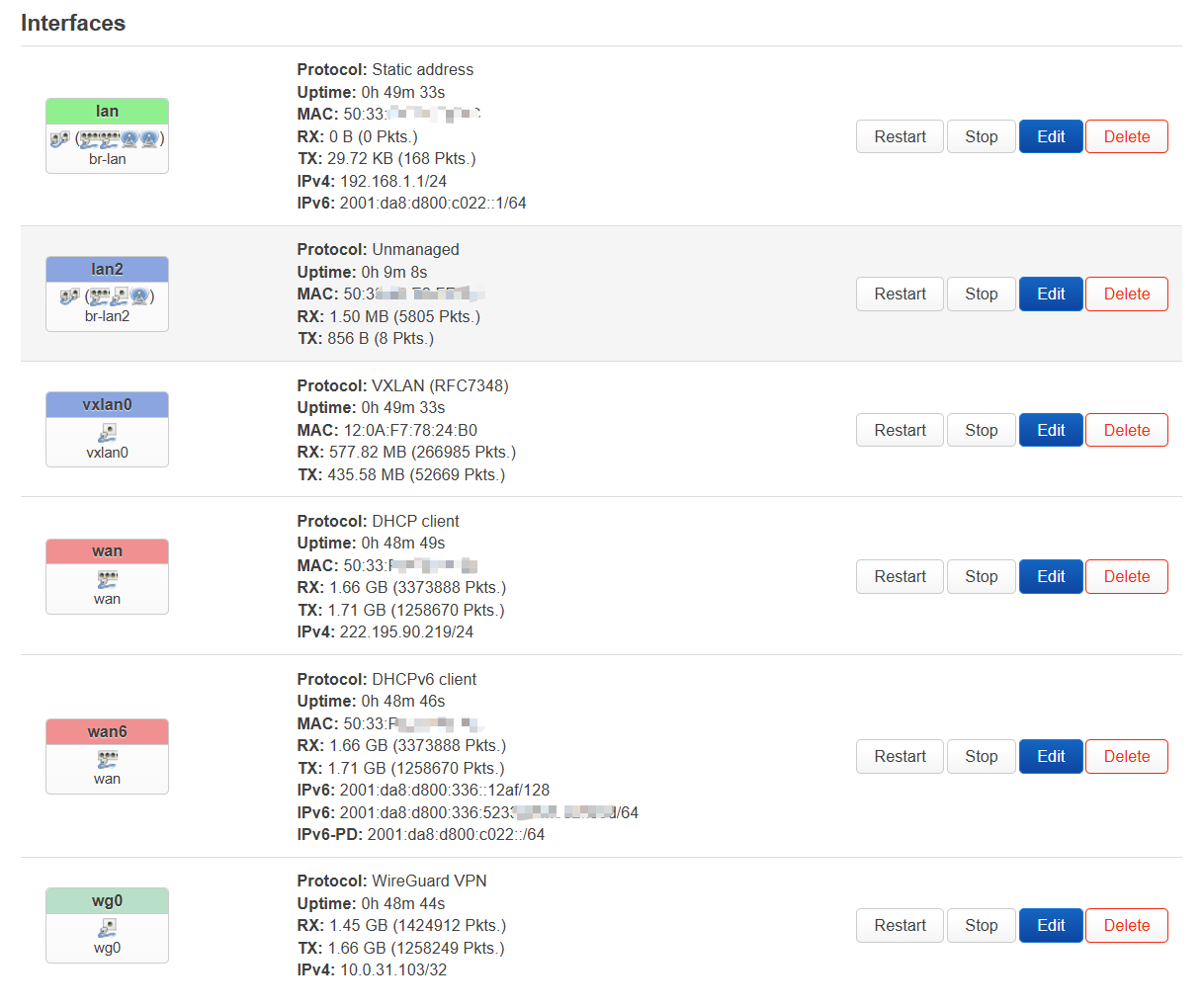
最终实现的效果
测速
最后的接口示例:
随着做种资源原来越多,原本 4T + 2T 的机械硬盘配置不够用了。即使已经做了很多缓解措施,比如将比较大的视频文件转成 av1 编码(4k h264可以达到30G -> 6G的效果),仍然是捉襟见肘。随着最近想要下载一些 VR 游戏资源,硬盘不够用了越来越明显,看来添加硬盘是必须做的了。
同时我也觉得现有的数据管理有点不安全。目前只对一些文档数据做了备份,然而一些虚拟机磁盘镜像,比如主力使用的 windows 虚拟机的磁盘镜像,由于数据量太大,只存了一份。这些都是单点故障点,一旦硬盘坏了,对我的影响是非常大的。
为了解决容量和安全性的问题,决定在台式机上添加一些机械硬盘组 raid10。
为什么是 raid10
有两个原因,一个是 raid 10 重建时更安全。不像 raid 5 重建时存在 URE 问题(指需要读取阵列全部的数据,数据量大,有很大概率遇到 URE 错误导致重建失败),raid 10 只需要读取一个 mirror 中另一块盘的数据,数据量很小。第二是 raid 10 远比其它 raid 灵活。raid 10 两块硬盘为 1 组,只需要保证两块硬盘容量相同即可。而其它 raid 均需要所有盘容量相同,这意味着我得一次性把所有的盘都买来,而一块 14T 的企业盘需要一千多,3-4 块一次购入显然成本太高。另外,raid 10 后续扩容也非常容易,插入即可扩容。而其它 raid 则需要重建整个阵列,非常费时。
这篇文章主要记录下硬件的升级点,以及人生第二次装机总结的一些经验。
epilogue
经过 1 周的规划与实践,台式机终于升级完成。现在它真的成了一个 all in one 完全体了
然而也有一些之前没有考虑到的:
Update 2024/10/31
背景:串流软件不支持手动添加 ip,导致需要二层隧道连接两个路由器。
通过 mDNS proxy 实现本地发现
之前还研究过这类软件一般是怎么发现server的。发现确实有一些方法可以实现跨网络的发现。比如常见的“发现”协议(不知道术语是什么)有mDNS和upnp。是通过ipv4 multicast实现的,所以只要能proxy多播包,就可以实现在两个网络互相发现。
2024/4/17 update: 今天在搜索 vxlan 时发现了一篇博客也遇到了这个问题。他的解决方案是通过设置 bridge-nf-call-iptables 使得桥接的数据包也通过 iptable,然后再通过 iptable 修正 MSS。因此其方案对于 UDP 仍然存在问题。不过将 bridge 的包进行三层的处理的思路是一样的。在 OpenWrt 设备间使用 VXLAN 创建隧道 – t123yh's Blog 看来这个问题并不是 gre 才会有的。那有没有更加现代的二层隧道协议,能够自动解决这个问题呢?
隧道方案如下图所示:
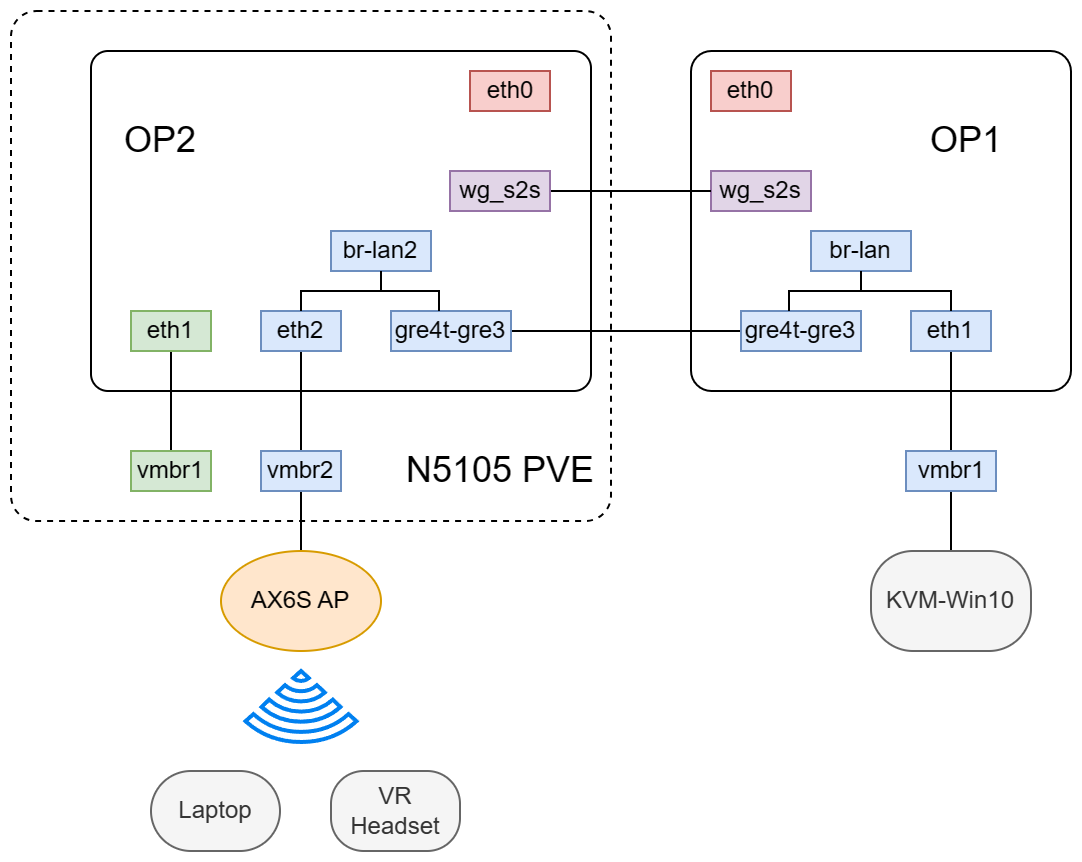
op2 是 PVE Host 上一个容器
op2是PVE上的一个LXC容器,分配了eth0, eth1, eth2分别对应wan, lan1, lan2
VLAN 切换 SSID 方案
刚开始想了一个更复杂不用改动AP网线的方案。将AP通过一根线和软路由连接,然后创建2个vlan。AP上,创建两个不同SSID绑定到不同VLAN接口上。这样就可以通过更改连接的WiFi来切换lan1和lan2了。不过PVE上vlan貌似配置有点复杂:可能需要创建一个vlan awareness的vmbr1,然后op2连接到vmbr1的eth1和eth2指定不同vlan id。但是我没想清楚vmbr1下untagged的接口怎么办?vmbr1设置了awareness后还能连接untagged的端口吗?因为不太了解PVE VLAN awareness bridge的更详细内容,加上路由器就在手边,换条线也很快,因此就没有使用该方案。
实现上述方案后,确实让一开始的 VR 串流软件可以工作了,但是确遇到了一些意外的问题。
我发现我的手机平板都无法使用 moonlight 串流我位于 op1 下的台式机 KVM-win10 了。
以前也遇到这样能 ping 通,但是一发送数据就出问题的现象。问题一般是哪里的接口 MTU 设置不正确导致的,因此这次也是往 MTU 这方面排查问题。 加上之前遇到的 MSS 问题,于是这次相当于把我知道的都结合起来,看能否解决这个问题。
学校提供了 ipv6,我的许多服务都可以使用 v6 访问。但是学校提供的 PD 可能会变,虽然使用 ddns 可以将 v6 地址映射到固定的域名,但是 ddns 有延迟性。因此最好的解决办法仍然是给机器设置静态 ip。
p.s. 短期重启网卡 PD 不会变,但是如果长期离线再上线就可能变,类似于 dhcp。
宿舍的 v6 wan 口无法设置静态 ip,因为学校路由器要求设备必须发了 RS 才会路由该包。
信智楼则可以静态设置。当访问外网时,学校路由器不会检查源地址,会直接路由出去。等接收到回包时,学校路由器看到目的地址为设置的静态地址,会在广播域上发送 NS,我自己路由的 wan 口接收到 NS 后响应 NA(v6 版的 ARP 过程)。学校路由器便知道了我路由器 wan 口的 mac 地址,于是将包发送给我的路由器 wan 口。
虽然信智楼可以静态设置 v6,但是仅限于 wan 口。lan 下面的设备如果手动设置了静态 v6,是无法正常上网的。重复上过程会发现学校仍然会正常把包路由出去,但是收到回包后,会像之前一样发送 NS。而我们路由器的 wan 口接收到 NS 后,根本不会响应 NA(因为不是自己的 v6 地址)。LAN 和 WAN 又不是一个广播域,因此收不到 NS。从而导致学校路由器并不会把回包交给我们。
但其实上面的需求是可以实现的,我们需要一个叫做 NDP proxy 的软件。
我比较喜欢 hexo 的 tags 字云的效果,不过由于以下原因,我打算迁移到新的静态博客框架 mkdocs material theme
TODO
参考方案
p.s. 由于我使用的 markdown 编辑器的原因,才发现标准 MD 中 list 前面需要有一个空行。也就是迄今写的博客均踩了这个坑。。。而 mkdocs 不支持这个非标准行为,以后慢慢更正吧
tsj 的 NAS 插墙上网口,笔记本同样插墙上网口,然后使用 NAS 官方工具扫描不到设备。由于扫描不到设备所以不知道设备 ip,也就无法进一步配置。
那么是什么原因导致扫描不到呢,照理来说,NAS 和笔记本应该接在同一个交换机下,理应是互通的。在研究该问题过程中,查缺补漏了很多网络知识,特记录。
疑问一:学校为何插在相邻墙上的网口的机器分配到不同网段的 ip?比如 114.xxx 和 210.xxx 疑问二:宿舍路由器查看 wan 口邻居表,为何不同 ip 的 mac 地址是相同的?
我的台式机 pve 充当软路由功能,包含一个 openwrt LXC 容器。该容器使用了很长时间,配置了 wiregurad,以及复杂的防火墙和路由规则。但是在一开始创建 lxc 容器时,rootfs 选择了 x86/generic 版本。该版本实质上是 32 位的系统
Generic is for 32-bit-only hardware (either old hardware or some Atom processors), should be i686 Linux architecture, will work on Pentium 4 and later. Use this only if your hardware can't run the 64-bit version.
虽然不知道会对性能等有多大影响,但是对于有点完美主义的人来说还是无法接受。因此研究如何将其升级到 64 位版本。
本来以为应该是一件很简单的事情,但是阅读 openwrt wiki 后,发现并没有想象中的简单。并且也学习到了一些关于镜像、分区、文件系统的知识。特此记录。
PVE 用法、配置个人记录
涉及虚拟 cache 导致的同名和重名问题;重名问题 bank 和 L2 两种解决方法;进程切换时 TLB 的操作;什么时候需要显示地控制 cache 等。
ipv6 协议详细介绍了 ipv6 几种获得地址模式的区别:SLAAC, 无状态 DHCPv6 和 有状态 DHCPv6
另外介绍了下 openwrt 使用 relay 模式导致需要 ping wan 口才能通的原因
服务器有一些老计算卡如 P40,TitanV 都是有图形能力的,并且貌似性能还不错(比如 TitanV 有 3070 的性能)。还有一些老卡如 1080Ti 很少有人用,闲置太浪费了。
因此本着科学求实的精神,想探究下实验室这些卡的性能水平,为之后科研做铺垫。。。好吧,我编不下去了,就是想白嫖实验室显卡玩游戏。加上最近塞尔达王国之泪出了,之前捡垃圾时,见过用 P106 这种 100 块的 “1060” linux 下玩 switch 模拟器效果不错。而自己的显卡 rx550 根本带不动,流下了没钱买卡的泪水。
声明
效果



wolf 即插即用效果
由于我的台式机承载了 NAS,做种,Jellyfin,博客,文件同步等功能,已然成为一台服务器,因此其可靠性非常重要。但是我还是经历过几次由于网络故障导致其无法访问的情形,此时则只能去实验室维护比较麻烦,因此需要一个 IPMI 的管理功能,使得网络出故障情况下也能远程访问。
而家用 PC 主板很少有支持 IPMI 功能的,支持的板子一般都要 2000 元以上。因此需要一个成本低廉的方案,在网上搜索一阵后发现确实有基于树莓派 DIY 的方案,并且有一个比较大的开源项目 PI-KVM。
然而由于树莓派 400-500 昂贵的价格,使得 DIY 的成本仍然很高。直到我看到使用普通 arm 板子的方案。甚至可以使用 40 元的电视盒子。因此价格完全可以保证在 200 元以内,我觉的是一个可以接受的方案。
最后成本
推广一个自己的 github 仓库,期望共同完善。 阅读具体数学电子书籍时,由于经常需要查看某个编号的公式因此产生了这个项目,用于阅读时查阅公式 https://github.com/TheRainstorm/concrete_math_formulas
在具体数学 (Concrete Mathematics) 课本中,在解约瑟夫递推方程时,第一次介绍了成套方法 (repertoire method)。之后也使用这种方式求解各种递推方程。相信很多人第一次看到这种方法时都会感觉到不可思议——还能这样?虽然每一步都能看懂,但是就是不知道这种方法是怎么想到的。在查阅了一点资料后,我对该方法有了更多的认识。先说明一点,该方法并不是一种万能方法,实际上要求问题要有线性结构。
参考:linear algebra - Mathematical explanation for the Repertoire Method - Mathematics Stack Exchange
Microsoft PowerPoint - SC07_Optimization_Harris.ppt [Read-Only] (polytechnique.fr)
优化目标
是 memory bound 应用:
问题描述:
在 Docker 中使用 GPU 时遇到驱动版本冲突问题,具体表现如下:
nvcr.io/nvidia/cuda:12.8.0-base-ubuntu22.04 + --gpus all 时,nvidia-smi 能正确显示 CUDA 版本,PyTorch 可调用 GPU。ubuntu:22.04 自建镜像时,nvidia-smi 显示 CUDA 版本为 N/A,PyTorch 报错 No GPU driver found。若在镜像内手动安装驱动,则出现 NVML driver/library version mismatch(宿主机驱动版本与容器内不一致)。apt list 无 nvidia-driver)却能工作?
- 如何解决自定义镜像的驱动版本冲突?强制对齐宿主机和容器内驱动的小版本难度大,是否有通用方案?NVIDIA 官方镜像(如 nvcr.io/nvidia/cuda)通过 NVIDIA Container Toolkit 实现 GPU 透传,其核心机制为:
libcuda.so、libnvidia-ptxjitcompiler.so)到容器内的 /usr/local/nvidia/lib64。LD_LIBRARY_PATH,优先加载挂载的宿主机驱动库,而非容器内自带的库。查看 nvidia/cuda 镜像的 layer:Image Layer Details - nvidia/cuda:12.8.0-cudnn-devel-ubuntu22.04 | Docker Hub
其中确实大量设置了
然后容器内该目录却并不存在。不过通过 locate libcuda.so 发现确实和自己的镜像不同
➜ ~ dpkg -S /usr/lib/x86_64-linux-gnu/libcuda.so.535.183.01
libnvidia-compute-535:amd64: /usr/lib/x86_64-linux-gnu/libcuda.so.535.183.01
总结: