MTU 的那些坑(二层隧道组网)
背景¶
背景:串流软件不支持手动添加 ip,导致需要二层隧道连接两个路由器。
通过 mDNS proxy 实现本地发现
之前还研究过这类软件一般是怎么发现server的。发现确实有一些方法可以实现跨网络的发现。比如常见的“发现”协议(不知道术语是什么)有mDNS和upnp。是通过ipv4 multicast实现的,所以只要能proxy多播包,就可以实现在两个网络互相发现。
2024/4/17 update: 今天在搜索 vxlan 时发现了一篇博客也遇到了这个问题。他的解决方案是通过设置 bridge-nf-call-iptables 使得桥接的数据包也通过 iptable,然后再通过 iptable 修正 MSS。因此其方案对于 UDP 仍然存在问题。不过将 bridge 的包进行三层的处理的思路是一样的。在 OpenWrt 设备间使用 VXLAN 创建隧道 – t123yh's Blog 看来这个问题并不是 gre 才会有的。那有没有更加现代的二层隧道协议,能够自动解决这个问题呢?
二层隧道方案¶
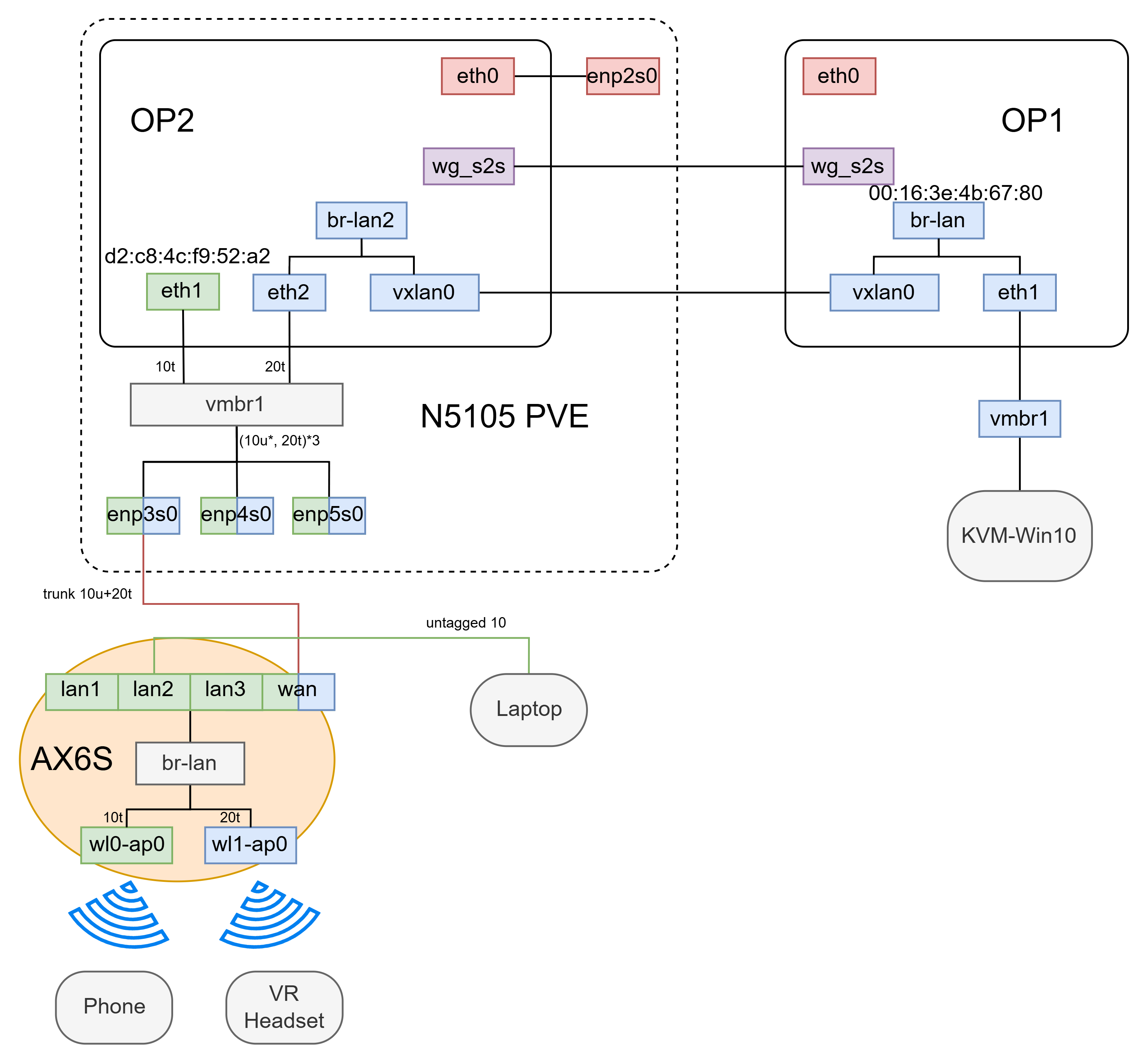
隧道方案如下图所示:
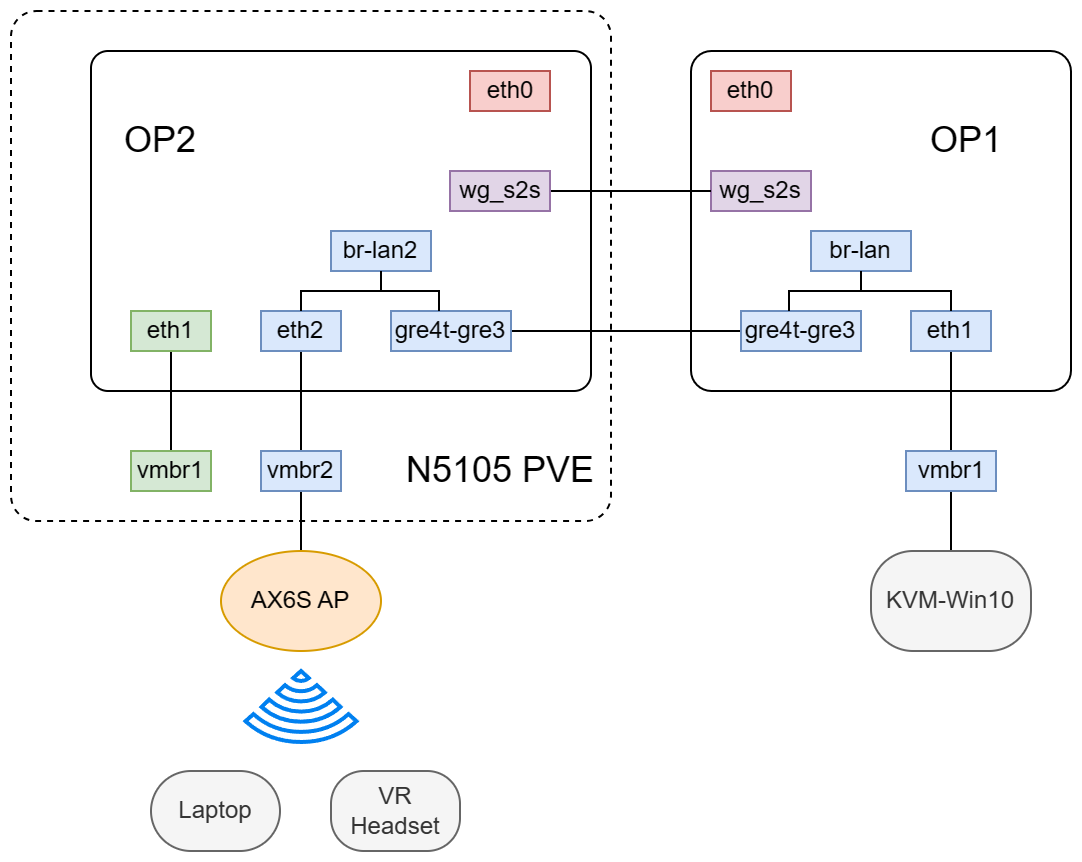
- 两个路由器间通过 WAN 口 IPv4 建立 GRE Tap 隧道
- op1 上将直接将 tap 接口桥接到到原有 br-lan 上
- op2 保留了原本自己的 lan,然后创建了一个新的 br-lan2,连接了 gre tap 接口和 eth2 接口。
op2 是 PVE Host 上一个容器
op2是PVE上的一个LXC容器,分配了eth0, eth1, eth2分别对应wan, lan1, lan2
- op2 侧将一个无线路由器连接到 PVE host(软路由)一个网口,该网口位于 PVE vmbr2 下。op2 eth2 也连接到了 vmbr2。
- 通过切换无线路由器连接到 PVE host 不同网口(对应 vmbr1 和 vmbr2),可以控制无线路由器位于 lan1 还是 lan2。
VLAN 切换 SSID 方案
刚开始想了一个更复杂不用改动AP网线的方案。将AP通过一根线和软路由连接,然后创建2个vlan。AP上,创建两个不同SSID绑定到不同VLAN接口上。这样就可以通过更改连接的WiFi来切换lan1和lan2了。不过PVE上vlan貌似配置有点复杂:可能需要创建一个vlan awareness的vmbr1,然后op2连接到vmbr1的eth1和eth2指定不同vlan id。但是我没想清楚vmbr1下untagged的接口怎么办?vmbr1设置了awareness后还能连接untagged的端口吗?因为不太了解PVE VLAN awareness bridge的更详细内容,加上路由器就在手边,换条线也很快,因此就没有使用该方案。
遇到的问题¶
实现上述方案后,确实让一开始的 VR 串流软件可以工作了,但是确遇到了一些意外的问题。
我发现我的手机平板都无法使用 moonlight 串流我位于 op1 下的台式机 KVM-win10 了。
- moonlight 显示在线(这个需要开启 MSS clamping),但是一连接就报错。报错让检查 UDP 端口 478000 是否开放。
- 笔记本同样连接的 WiFi,却确能够正常串流
以前也遇到这样能 ping 通,但是一发送数据就出问题的现象。问题一般是哪里的接口 MTU 设置不正确导致的,因此这次也是往 MTU 这方面排查问题。 加上之前遇到的 MSS 问题,于是这次相当于把我知道的都结合起来,看能否解决这个问题。
基础知识¶
IP 分片¶
MTU,链路层的概念,表示能承载的网络层及以上的包的大小。正常以太网帧的 payload 部分范围应该在 46B - 1500B 之间,也就是 MTU 最大为 1500。

当我们使用 GRE,Wireguard 等隧道时,实际的 MTU 需要减去额外 Header 的开销,因此就会小于 1500。比如 wg ipv4 = 1440, wg ipv6 = 1420。
当上层协议包大小超过链路层 MTU 时,我们需要一种机制将包拆分,然后合并(重组)。这个功能是在 IP 层实现的。IPv4 Header 中有 Flag 和 Fragment offset,用于实现分片与合并。

Don't fragment 标志
ipv4头中Flags可以设置DF flag,表示禁止分片。这样当需要分片时,router节点应该返回ICMP Fragmentation Needed (Type 3, Code 4)。ipv6由于禁止了router分片(只能通信端点进行分片),因此header中没有也不需要该标志。
ipv4 和 ipv6 分片的区别
ipv4中间路由器可以对包进行分片,最后所有的分片包在目的节点合并 而ipv6禁止了路由器对包进行分片,分片必须在源和目的节点上进行。因此通信节点间必须先进行PMTUD(路径MTU发现),否则遇到MTU不够时,中间节点会返回ICMPv6 Packet Too Big (Type 2)。
PMTUD¶
PMTUD,即 Path MTU Dsicovery,用于发现通信路径上的最大 MTU,用来避免分片。
PMTUD 常见的是基于 ICMP 的方法:
- 对于 IPv4,可以设置 DF 标志,如果收到 Fragmentation Needed,就减小 MTU(ICMP 数据中包含下一条需要的 MTU)
- 对于 IPv6,没有不分片标志。设置初始 MTU 为网卡 MTU,如果中间设备返回 ICMPv6 type 2 消息,就减少 MTU。
我们可以使用 ping 来测试
$ ping www.baidu.com -l 1372 -f
正在 Ping www.a.shifen.com [182.61.200.6] 具有 1372 字节的数据:
来自 182.61.200.6 的回复: 字节=1372 时间=33ms TTL=46
$ ping www.baidu.com -l 1373 -f
正在 Ping www.a.shifen.com [182.61.200.6] 具有 1373 字节的数据:
需要拆分数据包但是设置 DF。
linux ping 参数
使用-s指定数据部分大小,使用-M do禁止分片
可以看到,我到百度的 PTMU 为 1372(因为实际中经过了一个 1400 的 wg 隧道)
- 其中
-l指定 icmp data 部分,因此实际 ip 包大小为:20 + 8 + 1372 = 1400 -f禁用分片
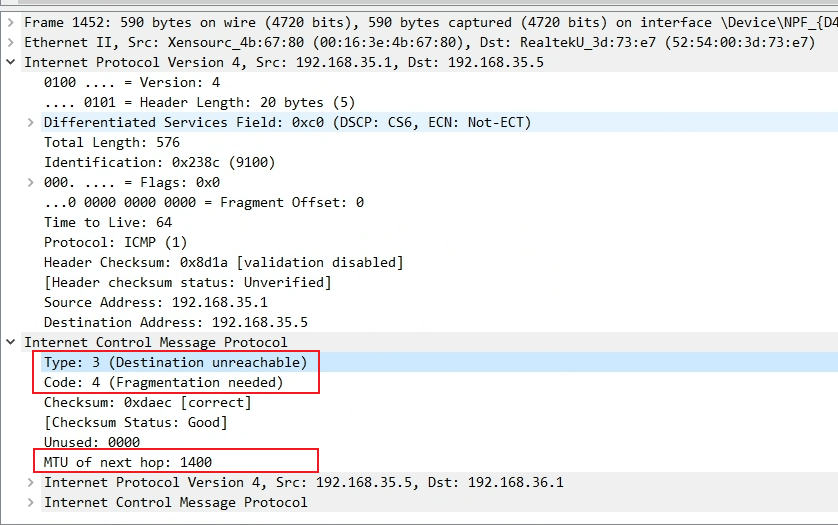
下图是使用 wireshark 抓到的 ICMP 包截图。type 为 destination unreachable,code 表明这是由于需要分片导致的。ICMP 中还包含了下一跳的 MTU(1400),并且将原本的 ip 包放在了结尾(可以看到原本的 IP 头,和 icmp 头)
PMTUD 失败与 MSS clamping¶
实际路由器由于安全考虑,会禁止转发 ICMP 消息,因此会导致 PMTUD 失效。这样对于 ipv6,可能会产生黑洞连接现象:TCP 三次握手成功(数据小于 MTU),但是发送数据没有响应(超过路径 MTU,包被丢弃)。
因此有些路由器提供了 MSS clamping 功能。路由器会对转发的 TCP 包的 MSS 进行修改。这样就能保证通信双方不会产生超过 MTU 的包,从而避免分片。
MSS 介绍
- MSS (maximum segment size) 是 TCP 中的概念,是连接双方能够接收的最大 segment 大小。
- MSS = MTU - IP header - TCP header。MTU 为 1500 时,MSS 为 1460
- MSS 会在 TCP 三次握手时进行协商,作为 TCP 头中 option 的内容。[并且只能在 SYNC 被设置时才能包含。](https://en.wikipedia.org/wiki/Transmission_Control_Protocol#:~:text=urgent%20data%20byte.-,Options,-(Variable%200%E2%80%93320)
MSS clamping 基于 iptable 实现。可以设置静态的数值,也可以设置成根据出口网卡 MTU 自动设置。
# 固定设置成1460
iptables -t mangle -A POSTROUTING -p tcp --tcp-flags SYN,RST SYN -o eth0 -j TCPMSS --set-mss 1460
# 根据PMTU自动设置
iptables -t mangle -A POSTROUTING -p tcp --tcp-flags SYN,RST SYN -o eth0 -j TCPMSS --clamp-mss-to-pmtu
openwrt 只对 forward 进行 MSS clamping?
openwrt开启 MSS clamping后,会在mangle_forward中添加以下规则。因此貌似只对forward生效
chain mangle_forward {
type filter hook forward priority mangle; policy accept;
iifname "warp" tcp flags syn tcp option maxseg size set rt mtu comment "!fw4: Zone warp IPv4/IPv6 ingress MTU fixing"
oifname "warp" tcp flags syn tcp option maxseg size set rt mtu comment "!fw4: Zone warp IPv4/IPv6 egress MTU fixing"
}
MSS clamping 是双向的
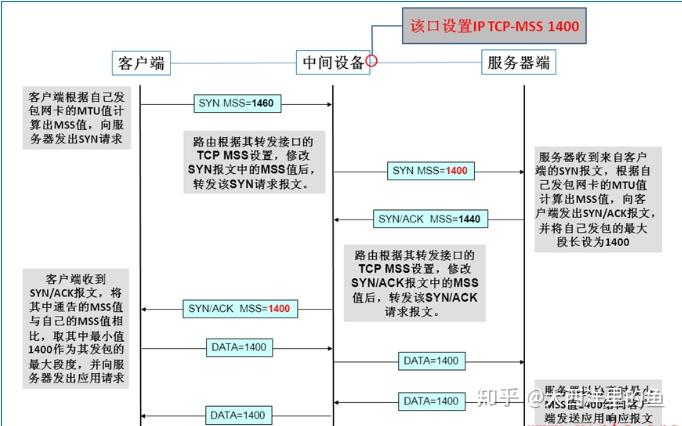
MTU的影响是单项的,即路由器往一个接口转发时,如果包大于接口MTU,就会进行分片。MSS clamping后,从该接口进入和出去的包都会被修改MSS。这里列一张参考文献中的图
Openwrt 的 MSS 功能放在防火墙 Zone 设置中(毕竟是基于 iptable 的,确实是防火墙功能),默认 WAN zone 的 MSS clamping 是勾选上的。如果有 wireguard 等隧道接口的话,建议也勾上,因此这样可以避免在路由器上分片,提升 TCP 性能。
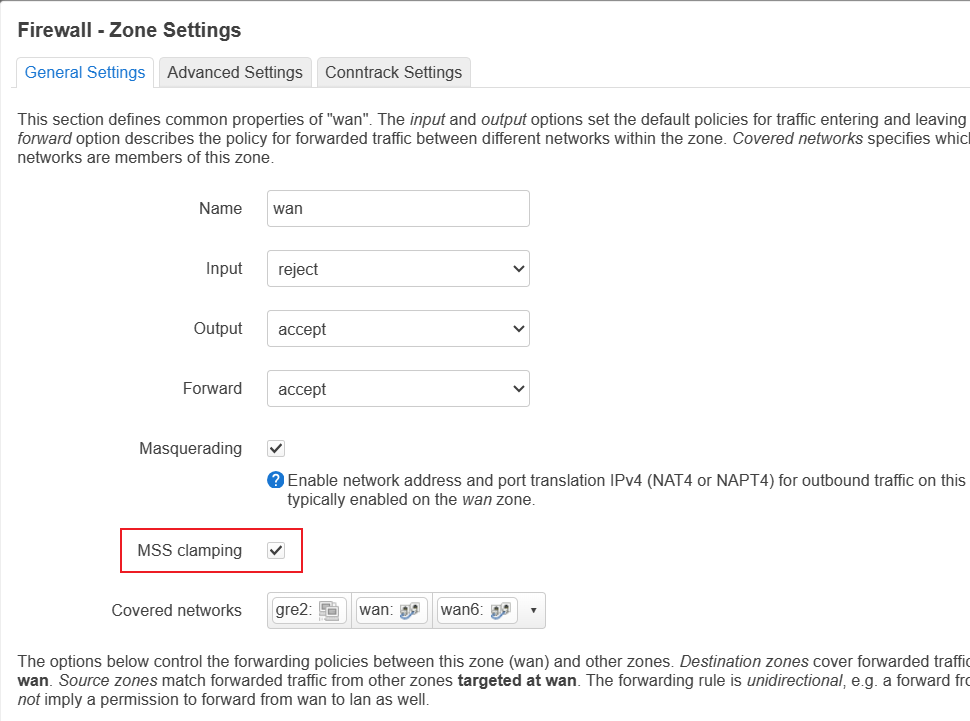
MTU 1508?¶
How to correctly set MTU of all my network interfaces (wan and lan)? - Installing and Using OpenWrt / Network and Wireless Configuration - OpenWrt Forum RFC 4638 - Accommodating a Maximum Transit Unit/Maximum Receive Unit (MTU/MRU) Greater Than 1492 in the Point-to-Point Protocol over Ethernet (PPPoE) (ietf.org)
参考资料¶
- 提到隧道往往需要限制 MSS 来避免分片:什么是 MSS(最大分段大小)? | Cloudflare (cloudflare-cn.com)
- 提到了 GRE 下 MSS 的计算:什么是 GRE 隧道?| GRE 协议如何工作 | Cloudflare (cloudflare-cn.com)
- 同样介绍了 MTU, MSS, PMTUD 联系:MTU TCP-MSS 详解 - 知乎 (zhihu.com)
- 提到了 1)v4 和 v6 的差异;2)中间路由器禁用 ICMP 导致黑洞连接现象;3)有些路由器提供 MSS 方案解决 PMTUD 失败的问题。Path MTU Discovery - Wikipedia
- PMTUD 导致 black holes:Black hole (networking) - Wikipedia
- openwrt 默认 wan 是 MSS clamping 的,只影响 forward,不影响 output。Firewall mtu_fix confusion - Talk about Documentation - OpenWrt Forum
- iptable TCPMSS target:Linux Packet Filtering and iptables - TCPMSS target (linuxtopia.org)
定位问题(但无法解决)¶
实验一:设置 bridge MTU 不影响接收只影响发送¶
kvm-win10 ping op1,经过的路径:
虽然 op1 br-lan mtu 已经设置成了 1280,但是实际上由于包是从 eth1 进入的,所以并不会丢掉。
- 中途 vmbr1 没有把包丢掉,我猜测是因为底层的接口实际 MTU 都是 1500 的,因此能够接收就不会丢掉。和 bridge 自身 MTU 没有关系
然后可以发现op1 response 时根据 br-lan 的 MTU 进行了分片,这是符合 MTU 一开始的设计的。
$ ping 192.168.35.1 -l 1472 -f
正在 Ping 192.168.35.1 具有 1472 字节的数据:
来自 192.168.35.1 的回复: 字节=1472 时间<1ms TTL=64
来自 192.168.35.1 的回复: 字节=1472 时间<1ms TTL=64
root@op1 ➜ ~ tcpdump -ni eth1 icmp and host 192.168.35.5
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on eth1, link-type EN10MB (Ethernet), snapshot length 262144 bytes
20:24:59.427833 IP 192.168.35.5 > 192.168.35.1: ICMP echo request, id 1, seq 1386, length 1480
20:24:59.427856 IP 192.168.35.1 > 192.168.35.5: ICMP echo reply, id 1, seq 1386, length 1256
20:24:59.427858 IP 192.168.35.1 > 192.168.35.5: ip-proto-1
实验二:同一个二层无法发 ICMP unreachable¶
还是上一个实验,把其中一个接口 mtu 调小:
设置 eth1 mtu 后。完全 ping 不通,op1 上 tcpdump 抓不到任何包,只有 pve vmbr1 上能抓到。 此时即使是允许分片,也是一样的现象。
产生该现象的原因是,op1 eth1 的 mtu 小了,包根本传不到 op1。因为它们位于同一个二层,没有路由器负责分片。
而 op1 又没法返回 ICMP 报错信息(因为这里 op1 不做为路由器),因此 kvm-win10 仍然继续以该大小包发送。
下一个实验表明,此时如果收到 ICMP 报错,系统就会调整 PMTU,在下次发送 icmp request 时就进行分片。
实验三:ICMP 影响系统 PMTU 缓存¶
op1 和 op2 通过 wireguard 隧道 wg_s2s 连接,而该隧道我将 MTU 设置成了 1400。当 kvm-win10 ping op2 的 wg 地址时,就会经过该隧道。大致过程:
可以发现不允许分片时,无法 ping 通,路由器返回 ICMP 报错。允许分片就可以正常 ping 通了。
$ ping 10.0.32.2 -l 1373 -f
正在 Ping 10.0.32.2 具有 1373 字节的数据:
来自 192.168.35.1 的回复: 需要拆分数据包但是设置 DF。
需要拆分数据包但是设置 DF。
需要拆分数据包但是设置 DF。
$ ping 10.0.32.2 -l 1373
正在 Ping 10.0.32.2 具有 1373 字节的数据:
来自 10.0.32.2 的回复: 字节=1373 时间=2ms TTL=63
来自 10.0.32.2 的回复: 字节=1373 时间=2ms TTL=63
并且 tcpdump 抓包可以看到第二次 ping 时,kvm-win10 已经提前将包进行分片了。
- 第一条
192.168.35.5 > 10.0.32.2,length 还是 1281 (1373+8) - 第二次 echo request 就已经变成连续两条
192.168.35.5 > 10.0.32.2了。(长度是 1376 而不是 MTU 对应的 1400 - 20(ip header) = 1380,是因为 ipv4 分片需要 8 字节对齐)
root@op1 ➜ ~ tcpdump -ni eth1 icmp and host 192.168.35.5
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on eth1, link-type EN10MB (Ethernet), snapshot length 262144 bytes
20:45:09.452565 IP 192.168.35.5 > 10.0.32.2: ICMP echo request, id 1, seq 1400, length 1381
20:45:09.452590 IP 192.168.35.1 > 192.168.35.5: ICMP 10.0.32.2 unreachable - need to frag (mtu 1400), length 556
20:45:17.217676 IP 192.168.35.5 > 10.0.32.2: ICMP echo request, id 1, seq 1403, length 1376
20:45:17.217681 IP 192.168.35.5 > 10.0.32.2: ip-proto-1
20:45:17.219738 IP 10.0.32.2 > 192.168.35.5: ICMP echo reply, id 1, seq 1403, length 1256
20:45:17.219741 IP 10.0.32.2 > 192.168.35.5: ip-proto-1
而要想提前分片,表明 OS 需要缓存目的地址的 PMTU,windows 有命令可以查看 PMTU
可以看到目的地址已经被设置成了 1400
接口 16: 以太网 2
PMTU 目标地址 下一个跃点地址
---- --------------------------------------------- -------------------------
1400 10.0.32.2 192.168.35.1
1500 20.42.65.91 192.168.35.1
1500 39.91.134.53 192.168.35.1
之后再发送大于 PMTU 的包且禁止分片时,windows 就会直接提示需要分片,而不会把包发出去,因此收不到来自路由器的 ICMP 报错消息。
如果一开始不限制分片
如果没有建立正确PMTU前发送一个大包,则路由器不会返回ICMP need fragment,而是直接分片传输。这样其实并不能学习到PMTU。
实验四:GRE Tap 隧道导致二层 MTU 不一致¶
由于 GRE Tap 的存在,导致原本全部都是 1500MTU 的二层里,出现了 1284 的隧道通路。因此只要大于该 MTU 的包通过该通路就会被丢弃,并且不会返回 ICMP,从而导致黑洞。
op1 下的 KVM-win10 ping op2 下的笔记本时,只要 icmp data 大于 1256 就会导致该现象。即使允许分片,也 ping 不通。
$ ping 192.168.35.180 -l 1256
正在 Ping 192.168.35.180 具有 1256 字节的数据:
来自 192.168.35.180 的回复: 字节=1256 时间=2ms TTL=128
来自 192.168.35.180 的回复: 字节=1256 时间=2ms TTL=128
$ ping 192.168.35.180 -l 1257
正在 Ping 192.168.35.180 具有 1257 字节的数据:
Control-C
总结与思考¶
- 原因在于二层 MTU 不一致,导致包经过一个更小的通路时既无法分片,也无法返回 ICMP 报错(否则设置了 PMTU,下一次就可以通过),从而导致黑洞。
- 对于 TCP 还能通过 MSS clamping 解决,但是对于 UDP 就没有办法了
- 如果二层隧道需要保证 MTU 一致,那用途是否太小?假设隧道 MTU 小于 1500,那么所有 1500 的设备都不能接入这个隧道。感觉只能连入几台可以手动调整 MTU 的设备。
- 疑点:
- 为什么笔记本可以正确连接,而手机平板不行。wireshark 抓包时,确实笔记本的包更小,不会超过 MTU。
- OS 不同?windows 可能自己做了 PMTUD
- 为什么笔记本可以正确连接,而手机平板不行。wireshark 抓包时,确实笔记本的包更小,不会超过 MTU。
TCP MSS 工作的条件
关于这点,做的实验数据没记录好。但是按照我模糊的记忆,一开始MSS其实并没有起作用。先要起作用,可能除了开启MSS clamping,还需要设置br-lan的MTU为和gre-tap的一样。否则仍然是按照 bridge的 MTU进行 clamping的。
可能的解决?¶
- 设置两端设备的 MTU
- 不知道 Android 如何设置手动设置 MTU
- 发现仅设置 windows 的 MTU 不行
- windows 上设置目标的 PMTU?(但是 MTU 单向的,貌似影响不到对面发包。但是也许串流场景对面发不了很大的包?)
- 发现 windows 设置不了,只能接收到 ICMP 时自己改
- 有没有 L2 上的 PMTUD?或者不基于 ICMP 不就行了?
- ARP proxy,让两边通信实际并不直接通信(走 gre 隧道),而是让路由器路由一下,比如通过 wg 隧道通信?
解决了?¶
2024/03/17
在学习 nft 时,偶然看到一个使用 nft 将 bridge 改为 routing 的写法。
# redirect tcp:http from 192.160.0.0/16 to local machine for routing instead of bridging
# assumes 00:11:22:33:44:55 is local MAC address.
bridge input meta iif eth0 ip saddr 192.168.0.0/16 tcp dport 80 meta pkttype set unicast ether daddr set 00:11:22:33:44:55
搜索一下,真的有这种做法,用于实现中间人攻击
Bridge + nftables: How to redirect incoming HTTP/HTTPS traffic to local port 8080? - Server Fault

尝试后真的成功了
nft 将 bridge 转成 routing
- op1 和 op2 上都需要类似操作
- ether daddr set 设置的是路由器 bridge 的 mac 地址
# op1
# delete table bridge gre_tap_fix_mtu
add table bridge gre_tap_fix_mtu
add chain bridge gre_tap_fix_mtu c1 { type filter hook prerouting priority -301; }
add rule bridge gre_tap_fix_mtu c1 meta iifname eth1 ip daddr 192.168.35.0/24 meta pkttype set host ether daddr set 00:16:3e:4b:67:80 counter
mtr 测试,可以发现两边 ping 时,路由多了一跳。原本是直接发送,现在变成路由器转发一次
op1 lan 内设备访问两个设备,分别过 gre 隧道和不过
➜ ~ tracepath -n 192.168.35.126
1?: [LOCALHOST] pmtu 1500
1: 192.168.35.1 0.111ms
1: 192.168.35.1 0.066ms
2: 192.168.35.1 0.076ms pmtu 1370
2: 192.168.35.126 116.700ms reached
Resume: pmtu 1370 hops 2 back 2
➜ ~ tracepath -n 192.168.35.5
1?: [LOCALHOST] pmtu 1500
1: 192.168.35.5 0.185ms reached
1: 192.168.35.5 0.230ms reached
Resume: pmtu 1500 hops 1 back 1
➜ ~
但是发现,通信端点发来的包如果已经经过分片(之前学习了 PMTU),到达路由器时却会将其合并。然后路由器转发时再根据 bridge(br-lan, br-lan2) 的 MTU 进行分片,这导致仍然无法通过 GRE 隧道。 因此简单地设置了下 br-lan 的 MTU,一切就正常了。
ping 大包测试¶
kvm-win10 ping 对面设备,可以看到 ping 大包能够 ping 通了,说明路由器上进行了正确的分片。
$ ping 192.168.35.126 -l 2000
正在 Ping 192.168.35.126 具有 2000 字节的数据:
来自 192.168.35.126 的回复: 字节=2000 时间=80ms TTL=63
来自 192.168.35.126 的回复: 字节=2000 时间=95ms TTL=63
op1 上抓包结果
- eth1 收到 KVM-win10 的 echo request,是按照 1500 进行分片的(kvm-win10 的 MTU)
- op1 将其合并,总共 2008B
- 然后从 br-lan 转发出去(实际最终从 gre4t-gre3 出去),按照 1420 的 MTU 进行分片
- 从对面收到 echo reply,也是按照 1420 分片的(op2 上进行了和 op1 类似的操作,无论.126 的设备是按照多大的 MTU 发送的,op2 转发时就会按照 br-lan 的 MTU 进行分片)
# 从eth1 收到的
17:19:13.358784 eth1 P IP 192.168.35.5 > 192.168.35.126: ICMP echo request, id 1, seq 1988, length 1472
17:19:13.358785 eth1 P IP 192.168.35.5 > 192.168.35.126: ip-proto-1
# 合并
17:19:13.358785 br-lan In IP 192.168.35.5 > 192.168.35.126: ICMP echo request, id 1, seq 1988, length 2008
# 从br-lan 转发出去,进行分片
17:19:13.358832 br-lan Out IP 192.168.35.5 > 192.168.35.126: ICMP echo request, id 1, seq 1988, length 1400
17:19:13.358834 gre4t-gre3 Out IP 192.168.35.5 > 192.168.35.126: ICMP echo request, id 1, seq 1988, length 1400
17:19:13.358841 br-lan Out IP 192.168.35.5 > 192.168.35.126: ip-proto-1
17:19:13.358842 gre4t-gre3 Out IP 192.168.35.5 > 192.168.35.126: ip-proto-1
# 返回
# 收到的已经是分片的了,直接转发
17:19:13.438654 gre4t-gre3 P IP 192.168.35.126 > 192.168.35.5: ICMP echo reply, id 1, seq 1988, length 1400
17:19:13.438656 gre4t-gre3 P IP 192.168.35.126 > 192.168.35.5: ip-proto-1
17:19:13.438689 eth1 Out IP 192.168.35.126 > 192.168.35.5: ICMP echo reply, id 1, seq 1988, length 1400
17:19:13.438690 eth1 Out IP 192.168.35.126 > 192.168.35.5: ip-proto-1
TCP MSS 也是正常工作的¶
192.168.35.126 ssh 192.168.35.2
op2 上可以看到经过 gre4t-gre3 接口出去的 MSS 是 1380(对应 MTU 1420)
root@op2 ➜ ~ tcpdump -ni gre4t-gre3 tcp port 2202 and host 192.168.35.2 and 'tcp[tcpflags] & (tcp-syn) != 0'
17:29:15.468383 IP 192.168.35.126.55960 > 192.168.35.2.2202: Flags [S], seq 604249636, win 65535, options [mss 1380,sackOK,TS val 573389803 ecr 0,nop,wscale 9], length 0
17:29:15.661593 IP 192.168.35.2.2202 > 192.168.35.126.55960: Flags [S.], seq 353962643, ack 604249637, win 65160, options [mss 1380,sackOK,TS val 265849573 ecr 573389803,nop,wscale 7], length 0
op1 上更直观,192.168.35.2 刚开始的 MSS 是 1460,经过 br-lan Out 时就改为了 1380 了
root@op1 ➜ ~ tcpdump -ni any tcp port 2202 and host 192.168.35.2 and 'tcp[tcpflags] & (tcp-syn) != 0'
17:29:15.466272 gre4t-gre3 P IP 192.168.35.126.55960 > 192.168.35.2.2202: Flags [S], seq 604249636, win 65535, options [mss 1380,sackOK,TS val 573389803 ecr 0,nop,wscale 9], length 0
17:29:15.466306 eth1 Out IP 192.168.35.126.55960 > 192.168.35.2.2202: Flags [S], seq 604249636, win 65535, options [mss 1380,sackOK,TS val 573389803 ecr 0,nop,wscale 9], length 0
# 刚开始是1460
17:29:15.658494 eth1 P IP 192.168.35.2.2202 > 192.168.35.126.55960: Flags [S.], seq 353962643, ack 604249637, win 65160, options [mss 1460,sackOK,TS val 265849573 ecr 573389803,nop,wscale 7], length 0
17:29:15.658494 br-lan In IP 192.168.35.2.2202 > 192.168.35.126.55960: Flags [S.], seq 353962643, ack 604249637, win 65160, options [mss 1460,sackOK,TS val 265849573 ecr 573389803,nop,wscale 7], length 0
# 设置为1380
17:29:15.658511 br-lan Out IP 192.168.35.2.2202 > 192.168.35.126.55960: Flags [S.], seq 353962643, ack 604249637, win 65160, options [mss 1380,sackOK,TS val 265849573 ecr 573389803,nop,wscale 7], length 0
17:29:15.658514 gre4t-gre3 Out IP 192.168.35.2.2202 > 192.168.35.126.55960: Flags [S.], seq 353962643, ack 604249637, win 65160, options [mss 1380,sackOK,TS val 265849573 ecr 573389803,nop,wscale 7], length 0
nft 查看 MSS 被修改的过程¶
op2 侧的无线路由器下的手机(192.168.35.126)ssh op1(192.168.35.1)。op2 上使用 nft 抓 TCP sync 包
可以看到 ether daddr 被成功修改,包进入了 forward mangle,修改了 MSS
iif "br-lan2" ether saddr 5a:ff:4d:38:41:2f ether daddr ca:84:4a:ec:90:53 ip saddr 192.168.35.126 ip daddr 192.168.35.1,这里的 ether daddr 不是 op1 的 mac 地址,而是 op2 上 br-lan2 的 mac 地址。说明 nft bridge 规则生效了
# 手机 sync
trace id 938d2a85 inet fw4 trace_chain packet: iif "br-lan2" ether saddr 5a:ff:4d:38:41:2f ether daddr ca:84:4a:ec:90:53 ip saddr 192.168.35.126 ip daddr 192.168.35.1 ip dscp cs0 ip ecn not-ect ip ttl 64 ip id 7498 ip protocol tcp ip length 60 tcp sport 49780 tcp dport 2202 tcp flags == syn tcp window 65535
trace id f67d6b7e inet fw4 mangle_forward packet: iif "br-lan2" oif "br-lan2"
trace id f67d6b7e inet fw4 mangle_forward rule iifname { "br-lan2", "gre4t-gre3" } tcp flags syn tcp option maxseg size set rt mtu comment "!fw4: Zone lan2 IPv4/IPv6 ingress MTU fixing" (verdict continue)
trace id f67d6b7e inet fw4 mangle_forward rule oifname { "br-lan2", "gre4t-gre3" } tcp flags syn tcp option maxseg size set rt mtu comment "!fw4: Zone lan2 IPv4/IPv6 egress MTU fixing" (verdict continue)
trace id f67d6b7e inet fw4 mangle_forward verdict continue
trace id f67d6b7e inet fw4 mangle_forward policy accept
trace id f67d6b7e inet fw4 forward packet: iif "br-lan2" oif "br-lan2"
trace id f67d6b7e inet fw4 forward rule iifname { "br-lan2", "gre4t-gre3" } jump forward_lan2 comment "!fw4: Handle lan2 IPv4/IPv6 forward traffic" (verdict jump forward_lan2)
trace id f67d6b7e inet fw4 forward_lan2 rule jump accept_to_lan2 (verdict jump accept_to_lan2)
trace id f67d6b7e inet fw4 accept_to_lan2 rule oifname { "br-lan2", "gre4t-gre3" } counter packets 283334 bytes 42471975 accept comment "!fw4: accept lan2 IPv4/IPv6 traffic" (verdict accept)
trace id f67d6b7e inet fw4 mangle_postrouting packet: iif "br-lan2" oif "br-lan2"
trace id f67d6b7e inet fw4 mangle_postrouting verdict continue
trace id f67d6b7e inet fw4 mangle_postrouting policy accept
...
# op1 返回 sync同样经过了 MTU fix
trace id 3786311f inet fw4 trace_chain packet: iif "br-lan2" ether saddr 00:16:3e:4b:67:80 ether daddr 5a:ff:4d:38:41:2f ip saddr 192.168.35.1 ip daddr 192.168.35.126 ip dscp af21 ip ecn not-ect ip ttl 64 ip id 0 ip protocol tcp ip length 60 tcp sport 2202 tcp dport 49780 tcp flags == 0x12 tcp window 64860
trace id 3786311f inet fw4 prerouting packet: iif "br-lan2"
trace id 3786311f inet fw4 prerouting rule iifname { "br-lan2", "gre4t-gre3" } jump helper_lan2 comment "!fw4: Handle lan2 IPv4/IPv6 helper assignment" (verdict jump helper_lan2)
trace id 3786311f inet fw4 helper_lan2 verdict continue
trace id 3786311f inet fw4 prerouting verdict continue
trace id 3786311f inet fw4 prerouting policy accept
trace id 3786311f inet fw4 mangle_forward packet: iif "br-lan2" oif "br-lan2"
trace id 3786311f inet fw4 mangle_forward rule iifname { "br-lan2", "gre4t-gre3" } tcp flags syn tcp option maxseg size set rt mtu comment "!fw4: Zone lan2 IPv4/IPv6 ingress MTU fixing" (verdict continue)
trace id 3786311f inet fw4 mangle_forward rule oifname { "br-lan2", "gre4t-gre3" } tcp flags syn tcp option maxseg size set rt mtu comment "!fw4: Zone lan2 IPv4/IPv6 egress MTU fixing" (verdict continue)
trace id 3786311f inet fw4 mangle_forward verdict continue
trace id 3786311f inet fw4 mangle_forward policy accept
...
补充:访问 op2 lan1 优化¶
虽然 MTU 问题解决了,但是连接 op2 wifi 后访问 op2 自身时会发生绕路的情况(即 op2 上想要从 lan2 访问 lan)。
例子:直接 ping op2,会发现包从 eth2 进入后,会从 vxlan 出去,再wg_s2s 回,而不会直接 eth2 -> eth1。这可能是因为包已经被 bridge 拿走了,所以不会 eth2 -> eth1。这导致实际上延迟从 1ms 变为 2ms。
p.s 如果 op1 上原本是无法访问 op2 的话,这样还会导致连接 lan2 wifi 无法访问 lan 的情况。
root@op2 ➜ ~ tcpdump -ni any icmp and host 192.168.36.1
tcpdump: data link type LINUX_SLL2
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on any, link-type LINUX_SLL2 (Linux cooked v2), snapshot length 262144 bytes
20:36:40.191286 eth2 P IP 192.168.35.180 > 192.168.36.1: ICMP echo request, id 1, seq 2028, length 40
20:36:40.191305 vxlan0 Out IP 192.168.35.180 > 192.168.36.1: ICMP echo request, id 1, seq 2028, length 40
20:36:40.192829 wg_s2s In IP 192.168.35.180 > 192.168.36.1: ICMP echo request, id 1, seq 2028, length 40
20:36:40.192862 br-lan2 Out IP 192.168.36.1 > 192.168.35.180: ICMP echo reply, id 1, seq 2028, length 40
20:36:40.192867 eth2 Out IP 192.168.36.1 > 192.168.35.180: ICMP echo reply, id 1, seq 2028, length 40
解决办法:针对 lan1 的地址,也将 bridge 转成 route 即可。
改完后再抓包,可以发现包从 br-lan2 就 Input 了,不像之前得绕路从 wg_s2s input 的情况。
20:45:55.192422 eth2 P IP 192.168.35.180.31195 > 192.168.36.1.2202: Flags [.], ack 5648, win 8193, length 0
20:45:55.192422 br-lan2 In IP 192.168.35.180.31195 > 192.168.36.1.2202: Flags [.], ack 5648, win 8193, length 0
20:45:55.294526 br-lan2 Out IP 192.168.36.1.2202 > 192.168.35.180.31195: Flags [P.], seq 5648:5852, ack 1, win 502, length 204
20:45:55.294528 eth2 Out IP 192.168.36.1.2202 > 192.168.35.180.31195: Flags [P.], seq 5648:5852, ack 1, win 502, length 204
再次总结与思考¶
虽然成功解决了,现在 moonlight UDP 串流没有问题了。但是可能的问题还有:
- 现在两端发送和接收的每个 udp 包,都额外经过了一次分片和合并,是否对性能有较大影响?
- 同一侧的机器间访问,是否也需要路由器转发?这样是否有性能影响
- 发现居然不是,因为同一侧的机器大部分在进入 openwrt 之前,就已经在 pve host 的 vmbr 上已经进行转发了。
通过 DHCP option 设置所有设备 MTU¶
只要 dhcp server 启用了 mtu option,好像主流系统都会使用。正好我的 360t7 无法使用 nft bridge 命令导致分片损耗很大,可以试一试该方案。
VLAN 切换方案¶
- 避免需要反复插拔网线来切换 AP 所在的 lan
- AP 只用单根网线 连接路由器
- 注:这里使用了 vxlan
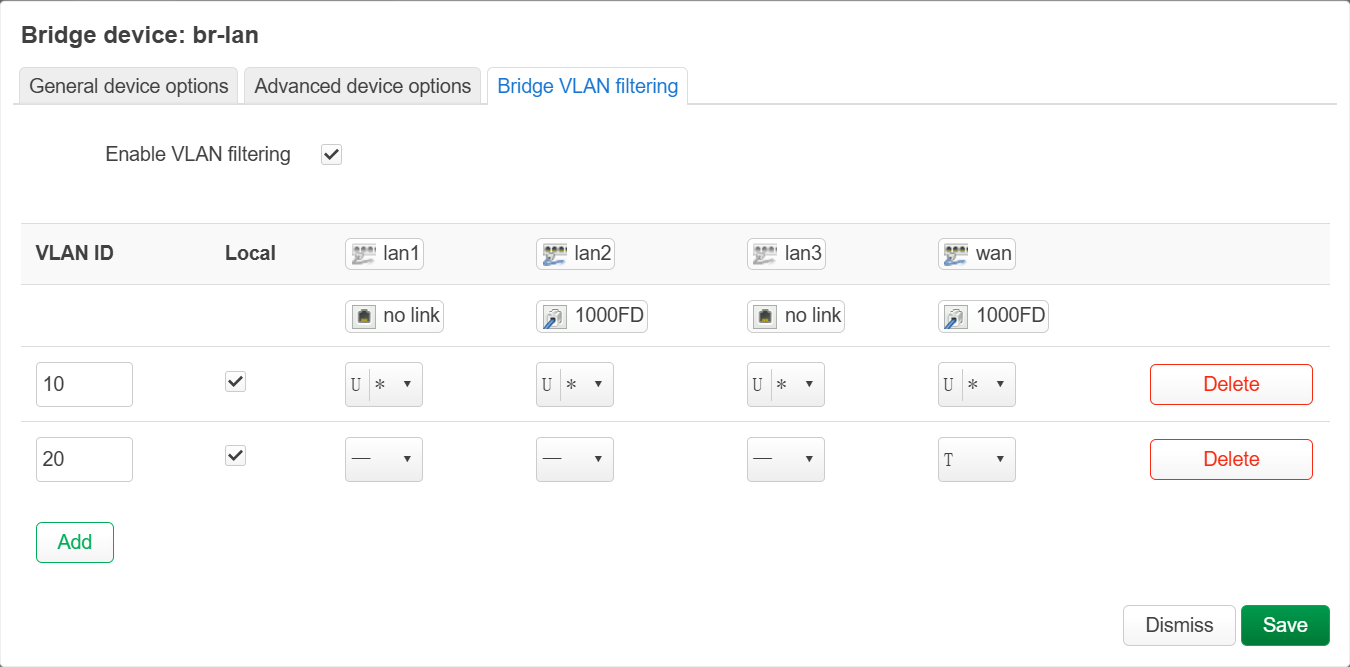
windows 获得错误的 v6 地址(RA 跨了网段)¶
笔记本通过网线连接到 AX6S AP。由于每个端口配置了 10 作为 pvid,并且 10 是 untagged 的,因此笔记本相当于接入了 VLAN10。
但是笔记本不知为何总会获得 VLAN20 的 ipv6 地址,而该地址是无法使用的。导致访问 B 站时可能遇到奇怪的卡顿,上网体验很差。
tcpdump 增加 -e,显示以太网帧后发现了问题。
- 由于每个 port 同时配置了 vlan 10 和 vlan 20,因此只要路由器发送 RA,就会在所有接口上发,不过会带上 vlan id。
- windows 接收到 tagged 的包,并不会丢弃,而是正常接收,这导致错误地配置了 SLAAC 的地址。
由于每个接口每 5 分钟对所有节点发送一次 RA,以下是抓到的 op2 和 op1 广播的 ra 消息。只要一接收到该消息,windows 就会出现错误的 v6 地址。
root@ax6s ➜ ~ tcpdump -nei lan3 -vvvv -tttt "icmp6 and (ip6[40] == 134 or ip6[40] == 133)" # rs, ra
2024-08-05 01:12:58.032179 d2:c8:4c:f9:52:a2 > 33:33:00:00:00:01, ethertype 802.1Q (0x8100), length 178: vlan 10, p 0, ethertype IPv6 (0x86dd), (flowlabel 0x0f2eb, hlim 255, next-header ICMPv6 (58) payload length: 120) fe80::d0c8:4cff:fef9:52a2 > ff02::1: [icmp6 sum ok] ICMP6, router advertisement, length 120
hop limit 64, Flags [other stateful], pref medium, router lifetime 1800s, reachable time 0ms, retrans timer 0ms
source link-address option (1), length 8 (1): d2:c8:4c:f9:52:a2
0x0000: d2c8 4cf9 52a2
mtu option (5), length 8 (1): 1492
0x0000: 0000 0000 05d4
prefix info option (3), length 32 (4): 2409:8a30:4ae:a540::/64, Flags [onlink, auto], valid time 258681s, pref. time 172281s
0x0000: 40c0 0003 f279 0002 a0f9 0000 0000 2409
0x0010: 8a30 04ae a540 0000 0000 0000 0000
route info option (24), length 24 (3): 2409:8a30:4ae:a540::/60, pref=medium, lifetime=1800s
0x0000: 3c00 0000 0708 2409 8a30 04ae a540 0000
0x0010: 0000 0000 0000
rdnss option (25), length 24 (3): lifetime 1800s, addr: 2409:8a30:4ae:a540::10
0x0000: 0000 0000 0708 2409 8a30 04ae a540 0000
0x0010: 0000 0000 0010
advertisement interval option (7), length 8 (1): 600000ms
0x0000: 0000 0009 27c0
2024-08-05 01:13:36.201962 00:16:3e:4b:67:80 > 33:33:00:00:00:01, ethertype 802.1Q (0x8100), length 154: vlan 20, p 0, ethertype IPv6 (0x86dd), (flowlabel 0x31634, hlim 255, next-header ICMPv6 (58) payload length: 96) fe80::216:3eff:fe4b:6780 > ff02::1: [icmp6 sum ok] ICMP6, router advertisement, length 96
hop limit 64, Flags [managed, other stateful], pref medium, router lifetime 1800s, reachable time 0ms, retrans timer 0ms
source link-address option (1), length 8 (1): 00:16:3e:4b:67:80
0x0000: 0016 3e4b 6780
mtu option (5), length 8 (1): 1370
0x0000: 0000 0000 055a
prefix info option (3), length 32 (4): 2001:da8:d800:c019::/64, Flags [onlink, auto], valid time 2443865s, pref. time 456665s
0x0000: 40c0 0025 4a59 0006 f7d9 0000 0000 2001
0x0010: 0da8 d800 c019 0000 0000 0000 0000
rdnss option (25), length 24 (3): lifetime 1800s, addr: fe80::216:3eff:fe4b:6780
0x0000: 0000 0000 0708 fe80 0000 0000 0000 0216
0x0010: 3eff fe4b 6780
advertisement interval option (7), length 8 (1): 600000ms
0x0000: 0000 0009 27c0
解决方法:设置 lan2 只能通过 wifi 接入,所有 lan 端口都不加入 vlan20(注意,wan 用于连接上级路由器 op2,因此需要保留 vlan20)
2024/12 更新 L2TPv3(failed)¶
请教一下群内大佬关于 vxlan 的问题,我现在有 B 和 C 两个设备通过 vxlan 连接到 A,B 和 C 都能访问 A,但是 B 和 C 之间不通,请问这是默认行为吗?B 访问 C 时,tcpdump 抓包能在 A 上抓到 arp 但是没有响应。
vxlan 不通的原因
- A 在 vxlan0 上收到 B -> C 的包,mac 地址是 B -> C,不是自己的,直接丢弃。
- 如果有 hairpin 功能,也许可行
- vxlan 设计的是多个机器通过虚拟端口间通信,就像在一个交换机上。我这里的情况,变成了希望从一个端口来回一趟。
意识到 gre 和 vxlan 这样的协议没有处理 MTU 问题,是因为他们的应用场景。GRE tap确实没想到只能在两个设备间 L2 连接有什么用。 vxlan 用于实现不同 VTEP 之间多对多连接(底层最好基于多播,或者在一个二层内,多跳的网络扩展性不好),可以用于数据中心连接多个机柜中的虚拟机。 至于二层组网场景,企业使用的协议是 L2TPv3 这种协议,v3 是版本号。L2TPv3 并且可以和普通以太网桥接起来,支持处理分片。关键词为 L2TPv3 Pseudowire
发现仍然还是不行,将不同 MTU 接口 bridge 在一起还是有问题
TheRainstorm, [2024/12/7 15:17]
请教一下群内大佬关于 vxlan 的问题,我现在有 B 和 C 两个设备通过 vxlan 连接到 A,B 和 C 都能访问 A,但是 B 和 C 之间不通,请问这是默认行为吗?B 访问 C 时,tcpdump 抓包能在 A 上抓到 arp 但是没有响应。
TheRainstorm, [2024/12/7 15:19]
创建 vxlan 的命令:ip link add vxlan0 type vxlan id 8 remote xxx dev eth0 dstport 4789
Ciel, [2024/12/7 15:19]
看起来你的A没有处理转发(?
TheRainstorm, [2024/12/7 15:20]
A 是 openwrt,转发是开的。并且理论上 in 和 out 的接口都是 vxlan0,所以应该也没有防火墙问题?
Miao Wang, [2024/12/7 15:20]
你 abc 三个机器上 vxlan 网络的 IP 是同一个网段?
TheRainstorm, [2024/12/7 15:22]
是的,都是 A 上 dhcp 下发的地址。B 是我手动添加的静态地址。A 上将 vxlan0 和 eth0 bridge 到了一起。B 和 C 都能访问 A 的 eth0 下设备,但是之间就不互通
Miao Wang, [2024/12/7 15:22]
这是期待的现象
Miao Wang, [2024/12/7 15:22]
vxlan 隧道是个多点的隧道
Miao Wang, [2024/12/7 15:23]
里面有个转发表
Miao Wang, [2024/12/7 15:23]
写明指定的 mac 地址要发到哪个隧道端点
Miao Wang, [2024/12/7 15:23]
而你 ip link add 里的 remote 是指没有查到的默认目标
Miao Wang, [2024/12/7 15:24]
所以当 B 访问 C 的时候,相当于是 A 收到了 B 发给 C 的包,不是发给自己的,丢掉
Miao Wang, [2024/12/7 15:25]
对于你的需求,看你 B 和 C 的访问,到底你是否想要经由 A 转发
Miao Wang, [2024/12/7 15:26]
如果需要,那么可能的一个操作是在 A 的 vxlan 接口上开 hairpin(我没试过)
Miao Wang, [2024/12/7 15:27]
你把以太网和 vxlan bridge 起来都是不对的
Miao Wang, [2024/12/7 15:27]
因为它们 mtu 不一样
Miao Wang, [2024/12/7 15:27]
而 vxlan 不支持分片
TheRainstorm, [2024/12/7 15:29]
这个确实,我之前踩了这个坑。后面发现使用 add rule bridge gre_tap_fix_mtu c1 meta iifname eth1 ip daddr 192.168.35.0/24 meta pkttype set host ether daddr set 00:16:3e:4b:67:80 counter 这样一条 nft 命令可以解决
TheRainstorm, [2024/12/7 15:30]
就是 nft 修改下目的 mac 地址,改为 A 的 bridge mac 地址。这样 A 就会对包在 3 层进行转发一次
Miao Wang, [2024/12/7 15:31]
哦,那也不是不可以
TheRainstorm, [2024/12/7 15:32]
A 转发的同时就会分片了,同时也可以使用 MSS clamping 修改 TCP 连接的 MSS 来避免分片
Miao Wang, [2024/12/7 15:33]
不是,我是说 B 和你被桥起来的 eth0 里面的设备的通信
Miao Wang, [2024/12/7 15:36]
因为这种通信不一定是 tcp,轮不到你改 mss;而且有些应用(比如路由协议)还对跳数有要求,你这个由 A 三层转发的话,就多出来了一跳
Miao Wang, [2024/12/7 15:37]
我给你一个一劳永逸的建议是,B 和 C 分别建立一个 l2tpv3 的隧道,在 A 上把两个隧道接口和 eth0 桥起来
Miao Wang, [2024/12/7 15:37]
vxlan 不适合你这种场景
Miao Wang, [2024/12/7 15:37]
l2tpv3 是点到点的隧道,而且支持分片
TheRainstorm, [2024/12/7 15:39]
就是本来 B 是直接发给 eth0 下的设备 D 的,B 分片是按 1500 分的,A 收到原本目的 mac 地址为 D 的包改为 A 自己的,就会传到 3 层处理。将分片合并后,按照 eth0 设置的 mtu(减去 VXLAN 的开销) 重新分片。相当与中间多了个分片合并的开销。对于 TCP 流量还可以使用 MSS clamping 消除这个开销,对于 UDP 确实就需要承受这个开销,但是至少不会出现大包不通的情况
Miao Wang, [2024/12/7 15:40]
B 的 vxlan mtu 小
Miao Wang, [2024/12/7 15:40]
你考虑一下 D 发给 B?
Miao Wang, [2024/12/7 15:41]
D 发出来的包是 1500,到 A 这里(注意是二层来的,目的 mac 是 B),由 A 的 bridge 二层转发给 vxlan 接口
Miao Wang, [2024/12/7 15:41]
然后超过 vxlan 接口的 mtu,丢弃
Miao Wang, [2024/12/7 15:43]
你要是强行把 vxlan 接口的 mtu 设置为 1500 也可以,那么就是 vxlan 在 underlay 网络发包的时候发现加上隧道头和 udp 头之后超过 underlay 的 mtu,丢弃
TheRainstorm, [2024/12/7 15:43]
哦,我描述不对。其实 B 和 A 都是路由器,我需要在 B 和 A 上都对本地 eth0 下设备发往对面(vxlan)的包使用那个 nft 命令
Miao Wang, [2024/12/7 15:44]
所以我觉得你的实现似乎很复杂,很麻烦,把不该用在这个场景下的东西拿了过来
Miao Wang, [2024/12/7 15:45]
你到底要二层通还是三层通,三层通直接用 gre 隧道,二层通的话用 l2tp 隧道
Miao Wang, [2024/12/7 15:45]
你现在似乎状态是,呈现的样子好像是二层的,但是实际上还是三层转发
TheRainstorm, [2024/12/7 15:46]
确实,我可以看看你说的 l2tpv3。
TheRainstorm, [2024/12/7 15:47]
不过对应用来说没关系,因为我只是需要二层设备发现的能力
Miao Wang, [2024/12/7 15:47]
嗯,vxlan 主要还是点到多点的用途,就是希望参与的每个节点直接通信
Miao Wang, [2024/12/7 15:47]
不过现在看似乎不太行。。。。
Miao Wang, [2024/12/7 15:47]
比如如果是局域网的广播包,你这个似乎就很难处理。。。。
Miao Wang, [2024/12/7 15:48]
就是 ip l2tp add tunnel,然后 ip l2tp add session 就好了
L2TP 配置¶
sudo ip l2tp add tunnel tunnel_id 100 peer_tunnel_id 1 encap udp local 222.195.72.114 remote 114.214.236.72 udp_sport 1701 udp_dport 1702
sudo ip l2tp add session tunnel_id 100 session_id 1 peer_session_id 1
ip l2tp add tunnel tunnel_id 1 peer_tunnel_id 100 encap udp remote 222.195.72.114 local 114.214.236.72 udp_sport 1702 udp_dport 1701
ip l2tp add session tunnel_id 1 session_id 1 peer_session_id 1
之后在 op1 上将 l2tpeth0 添加到 LAN bridge 即可。
17:11:10.199353 l2tpeth0 P IP 192.168.35.42 > 192.168.35.183: ICMP echo request, id 35, seq 17, length 64
17:11:10.199366 vxlan0 Out IP 192.168.35.42 > 192.168.35.183: ICMP echo request, id 35, seq 17, length 64
17:11:10.204473 vxlan0 P IP 192.168.35.183 > 192.168.35.42: ICMP echo reply, id 35, seq 17, length 64
17:11:10.204496 l2tpeth0 Out IP 192.168.35.183 > 192.168.35.42: ICMP echo reply, id 35, seq 17, length 64
openwrt L2TPv3 Pseudowire bridged to LAN¶
https://openwrt.org/docs/guide-user/network/tunneling_interface_protocols#l2tpv3_pseudowire_bridged_to_lan
发现配置文件选项不太一样,是早期的 openwrt 网络配置,interface 直接使用 type bridge,而不是一个 device
This example establishes a Pseudowire Tunnel and bridges it to the LAN ports. The existing lan interface is reused with protocol l2tp instead of static.
config interface 'lan'
option proto 'l2tp'
option type 'bridge'
option ifname 'eth0'
option ipaddr '192.168.1.1'
option netmask '255.255.255.0'
option localaddr '178.24.154.19'
option peeraddr '89.44.33.61'
option encap 'udp'
option sport '4000'
option dport '5410'
Pseudowire [Old OpenWrt Wiki] 仍然不支持 bridge 不同 MTU 的设备。
For now the setup works so both sides can ping each other. An ssh connection, however, is not either possible or freezes after a few seconds. The reason: The bridge for the L2TPv3 contains devices with different MTU3 . Furthermore, as the connection is bridged no routing happens and the MTU is not automatically adjusted by the router. All devices in the LAN usually use a MTU of 1500. The MTU of the L2TPv3 devices is about 1400. As the tunnel itself can not fragment packets all packets bigger than the MTU are lost. This happens at longer HTTP request, too. To solve the problem bridge firewalling and TCP MSS Clamping is used. Bridge firewalling means the iptables rules are used when a packet passes a bridge. Normally this should not work, as a bridge only works in Layer 2. However, if bridge firewalling is enabled in the kernel a bridge can work in Layer 2 as well as Layer 3. The following sysctl keys are used for this:
参考¶
- windows 查看 PMTU:Windows MTU active value after pmtu ? - Microsoft Community
- route some packets instead of bridging:nft 手册
- 使用 nft 在 bridge 上实现中间人攻击:Bridge + nftables: How to redirect incoming HTTP/HTTPS traffic to local port 8080? - Server Fault