再次理解 Cache 设计
涉及虚拟 cache 导致的同名和重名问题;重名问题 bank 和 L2 两种解决方法;进程切换时 TLB 的操作;什么时候需要显示地控制 cache 等。
虚拟 cache 的问题¶
这里的虚拟 cache 指的是 virtual index, virtual tag
虚拟 cache 位于 cpu 和 tlb 之间,由于 cache 命中就不需要 tlb 地址映射,因此不会对 CPU 频率造成负面影响。
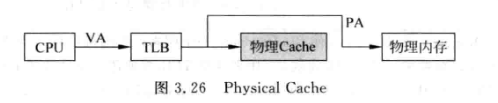
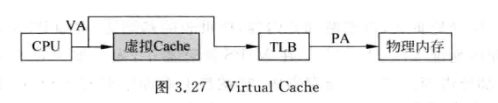
同名问题 (homonyms)¶
不同进程有着独立的虚拟地址空间,相同的虚拟地址对应不同的物理地址。
进程切换时,由于 cache 中采用 virtual tag,因此可能从 cache 中读取到其它进程的值。(物理 cache 没有这个问题)
解决方法:可能只能通过手动无效掉 cache 来解决。
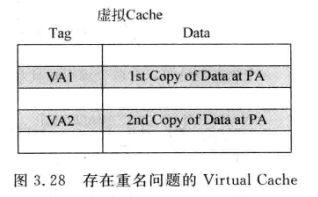
重名问题 (alias)¶
操作系统使用虚拟地址映射实现共享内存(不同虚拟地址 VA1,VA2,映射到相同物理地址 PA) 如果采用虚拟索引(virtual index),会带来重名问题:不同虚拟地址 VA1,VA2,映射到相同物理地址 PA,但是映射到不同 cache set
- 一份数据被存储了两遍
- 并且修改其中一个数据不会自动修改另一个
VIPT¶
VIPT 是一种并行了 TLB 和 cache 访问的实现方法,被广泛使用。利用了虚拟地址到物理地址 offset 部分是不变的特点。
- index ≤ offset 时等价于 PIPT,不同的是访问 TLB 和索引 cache line 可以并行
- index > offset 是才是 virtual index,且 virtual index = {a, offset},只有 a 部分是虚拟的
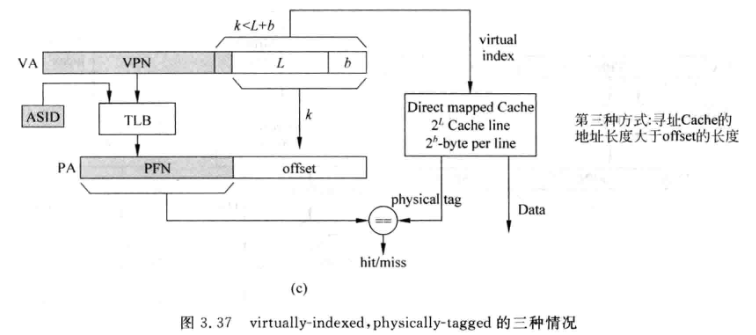
如果要求 index <= offset 的话,则 cache 一路的大小被限制为最大一页的大小(比如 4KB),增大 cache 的大小只能增加组相联度。
而重名问题只要是采用虚拟索引就会存在。因此 VIPT 当 index > offset 时,也会存在重名问题。因此解决重名问题非常重要。
重名解决方法¶
有两种解决重名的方法
- bank 方法本质还是将 VIPT 转换乘 PIPT
- L2 共享 cache 的方法则通过 L2 来判断 L1 是否发生了重名,然后无效掉重名部分
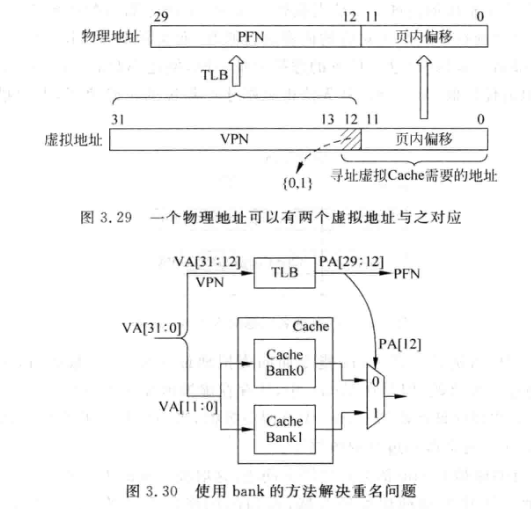
使用 bank 解决¶
- 图中直接映射 cache 大小为 8k,页大小为 4k。index -offset = 1。一个物理地址最多可能出现在两个 cache line
- 使用 VIPT 的好处便是能够并行访问 TLB 和 cache。如果 virtual index > page offset 位数,我们可以把所有可能的 physical index 都读出来(使用 bank 并行),然后再根据 TLB 翻译的结果多路选择。这样本质上又回到了 PIPT。
- cache 的 tag 和 data 需要分开存储,写入时,先读取 tag,命中后,再写 data 部分。
- 另一个理解:相当于 PFN 12 位为 0 的写入 bank0,为 1 的写入 bank1。物理地址是确定的,因此不会发生重名。
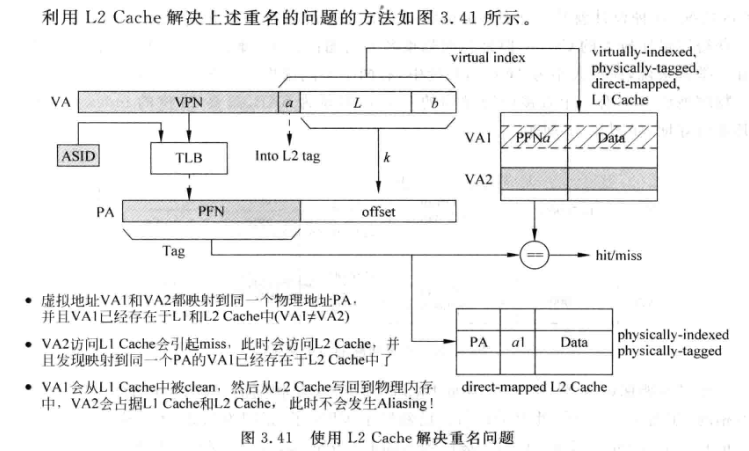
使用 L2 cache 解决¶
使用 L2 inclusive cache 解决虚拟 cache 重名问题。
- 思路:L1 cache 中重名的的虚拟地址,只存储一份,另一个无效掉 过程
- VA2 访问 L1 如果缺失,则 PA 访问 L2(使用 PIPT)
- L2 中如果已经存在 PA 的数据,则表示 L1 可能存在重名。
- L2 除了正常的 physical tag,还需要存储 L1 中 VA 的 a。如果 VA2 的 a 和存储的 a 不同,则表示 L1 存在重名的 cache line
- 重名的话,将 L1 中的 VA1(a+offset)cache line 置为无效
TLB ASID, cache 控制指令¶
TLB ASID¶
进程切换时,会切换页表。但是 TLB 中仍然保存着数据,因此可能会错误命中。
TLB 中缓存着页表项(虚拟页号到物理页号的映射),当进程切换后,理论上需要清空 TLB,可能浪费了有用的值。 为了解决低效的清空操作,引入了 ASID
既然无法直接从虚拟地址中判断它属于哪个进程,那么就为每个进程赋一个编号,每个进程中产生的虚拟地址都附上这个编号,这个编号就相当于是虚拟地址的一部分,这样不同进程的虚拟地址就肯定是不一样了。这个编号称为 PID(Process ID),当然更通用的叫法是 ASID(Address Space IDentifier)
同时 TLB 中还添加了 global 位,如果 G 位为 1,则忽略 ASID,用于实现全局共享。
cache 控制指令¶
可能存在一些操作,可能导致 cache 中数据和 ram 中不一致,需要手动管理 cache
cache 一致性
- DMA
- src 如果 dirty,需要写回内存
- 写入 dst 后,需要无效掉 cache 保证读到最新数据
- 自修改程序。程序可能有时需要动态生成指令执行,生成的指令会作为数据写入 d cache 中。由于 i cache 和 d cache 间不会自动同步
- 要想执行这些指令,需要将数据写回内存,并无效掉 i-cache 中对应指令。
- 有时就是需要将 cache 中 dirty 部分写回内存,比如 page fault 时替换掉 dirty 的页。
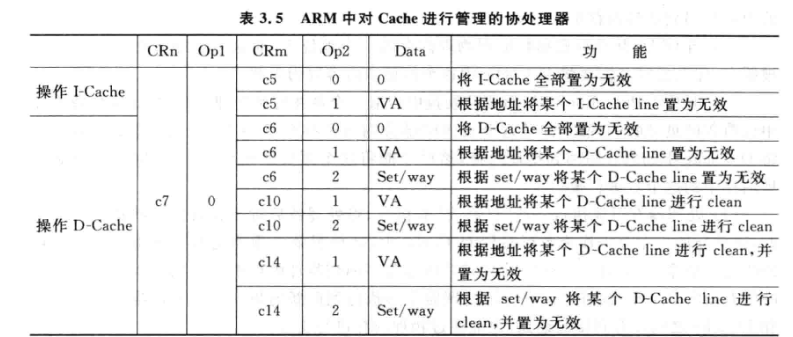
cache 操作可以总结为几种:clean,无效 (l) 能够将 I-Cache 内的所有 Cache Line 都置为无效; (2) 能够将 I-Cache 内的某个 Cache Line 置为无效; (3) 能够将 D-Cache 内的所有 Cache Line 进行 clean; (4) 能够将 D-Cache 内的某个 Cache Line 进行 clean; (5) 能够将 D-Cache 内的所有 Cache Line 进行 clean,并置为无效; (6) 能够将 D-Cache 内的某个 Cache Line 进行 clean,并置为无效。
定位 cache line 有几种方式
- set/way
- 地址(根据 cache 类型,可能是虚拟地址也可能是物理地址)
ARM¶
ARM 使用 CP15 协处理器(通过控制其寄存器来管理 cache)
MRC 指令将协处理器中某个寄存器的内容放到处理器内部指定的通用寄存器中, MCR 指令将处理器内部某个通用寄存器的内容放到协处理器内部指定的寄存器中
MIPS¶
MIPS 中使用 CACHE 指令

格式和 load,store 指令类似,计算 Effective addressEA = GPR[base] + offset

参考资料¶
- 超标量处理器设计,姚永斌,清华大学出版社