大纲
- how linux kernel boot
- kernel parameters
- grub
- how user space start
- init, systemd
- initial RAM filesystem
- Shell
- Disk and filesystem
- partitioning disk
- mount
- User identification, authentification, authorization
- identi
- user, group 定义
- PAM
- System configuration
- Logging
- Batch jobs
Disk and Filesystem¶
linux 分区¶
fdisk+mkfs+mount¶
使用 fdisk 给磁盘分区并挂载
列出磁盘信息
进入交互模式
fdisk 创建分区后
- 通过
mkfs.ext4 /dev/sdb1创建文件 ext4 系统(p.s. 注意:不要使用 sdb,而是 sdb1 指定分区)
mkfs.bfs mkfs.cramfs mkfs.ext2 mkfs.ext3 mkfs.ext4 mkfs.fat mkfs.minix mkfs.msdos mkfs.ntfs mkfs.vfat
- 通过
lsblk -f显示 UUID-f表示打印文件系统
-
在
/etc/fstab中添加挂载条目,然后mount -a表示挂载 fstab 中的所有条目 示例
- 修改挂载点目录权限,默认只有 root 用户可以访问
swap¶
sudo dd if=/dev/zero of=/swapfile bs=1G count=16
sudo mkswap swapfile
sudo swapon swapfile
#fstab
/swapfile none swap sw 0 0
mount¶
Fstab - Community Help Wiki (ubuntu.com)
mount 只能由 root 用户操作,导致 mount 的目录所有者为 root,普通用户无法访问
ext4 mount 选项中也没有指定 uid 的方式挂载(不像smb挂载时)ext4(5) - Linux manual page (man7.org)
其实上面根本不是问题,解决办法是:mount 之后使用 chown 命令将挂载的目录改为普通用户。由于用户信息是写入文件系统的,所以之后挂载时文件权限仍然是普通用户。
扩展分区 expand partition¶
ext4可以在线扩展分区(注意shrink是不行的)
方法列举:
- 使用gparted(简单,但是遇到device busy的情况也束手无策,不如命令行时知道问题出在哪)
- fdisk:需要先删除分区(注意不要删除文件系统signature),然后重新创建,保证起始sector相同。
- parted:有resize命令,扩展分区时更容易。但是由于每步操作都会立即执行,没有fdisk那样有安全感,最好还是不使用。
- resize2fs:默认是扩展所有空间。
fdisk
yfy@u22-game:~$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 98G 17G 76G 19% /
/dev/sda2 512M 6.1M 506M 2% /boot/efi
root@u22-game:/home/yfy# fdisk /dev/sda
Command (m for help): p
Disk /dev/sda: 120 GiB, 128849018880 bytes, 251658240 sectors
Disk model: QEMU HARDDISK
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: 43AAA442-6CCE-4AC2-9389-0EE427839D73
Device Start End Sectors Size Type
/dev/sda1 2048 4095 2048 1M BIOS boot
/dev/sda2 4096 1054719 1050624 513M EFI System
/dev/sda3 1054720 209713151 208658432 99.5G Linux filesystem
Command (m for help): F
Unpartitioned space /dev/sda: 20 GiB, 21475868160 bytes, 41945055 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
Start End Sectors Size
209713152 251658206 41945055 20G
Command (m for help): d
Partition number (1-3, default 3):
Partition 3 has been deleted.
Command (m for help): n
Partition number (3-128, default 3):
First sector (1054720-251658206, default 1054720):
Last sector, +/-sectors or +/-size{K,M,G,T,P} (1054720-251658206, default 251658206): +110G
Created a new partition 3 of type 'Linux filesystem' and of size 110 GiB.
Partition #3 contains a ext4 signature.
Do you want to remove the signature? [Y]es/[N]o: N
Command (m for help): w
The partition table has been altered.
Syncing disks.
root@u22-game:~# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 98G 17G 76G 19% /
root@u22-game:~# resize2fs /dev/sda3
resize2fs 1.46.5 (30-Dec-2021)
Filesystem at /dev/sda3 is mounted on /; on-line resizing required
old_desc_blocks = 13, new_desc_blocks = 14
The filesystem on /dev/sda3 is now 28835840 (4k) blocks long.
root@u22-game:~# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 108G 17G 86G 17% /
parted How to extend an EXT4 partition using parted and resize2fs - Knowledgebase - Cloud Services Store Limited resize2fs: 6.3. Resizing an Ext4 File System Red Hat Enterprise Linux 6 | Red Hat Customer Portal
千万注意 start sector 需要保持一样。fdisk 有时侯默认并不会保持不变。
Device or resource busy 怎么办¶
Command (m for help): w
The partition table has been altered.
Failed to remove partition 3 from system: Device or resource busy
Failed to remove partition 4 from system: Device or resource busy
Failed to update system information about partition 2: Device or resource busy
Failed to add partition 3 to system: Device or resource busy
The kernel still uses the old partitions. The new table will be used at the next reboot.
Syncing disks.
我重启后发现,分区已经更新了。resize2fs 即可
mkswap¶
linux 挂载¶
losetup¶
losetup is used to associate loop devices with regular files or block devices, to detach loop devices, and to query the status of a loop device.
losetup # 打印所有挂载的loopback设备
losetup -f --show default.img # 找到第一个未使用的loop设备,并打印,然后挂载default.img
losetup -d loopdev # detach指定loop设备
-r, --read-only # 只读挂载
磁盘镜像¶
用于挂载包含分区表的磁盘镜像
sudo kpartx -av 20240702_NanoKVM_Rev1_1_0.img # 创建 /dev/mapper/loopXpY
sudo kpartx -dv 20240702_NanoKVM_Rev1_1_0.img
测试磁盘速度¶
dd¶
使用 dd 简单测试速度。可以区分 usb 2.0 和 3.0;可以见识 PCIe 4.0 ssd 的速度。但是要进行更准确的测速,最好使用 fio。
注意需要开启 direct,否则需要从 userspace 复制到 kernel buffer,严重影响速度。block size 对速度影响很大。 Why is dd with the 'direct' (O_DIRECT) flag so dramatically faster?
- bs 影响很大
- /dev/null不需要使用oflag=direct
root@n5105-pve ➜ dd of=/dev/null if=/mnt/wd-passport/fio.img bs=1M count=2000
2000+0 records in
2000+0 records out
2097152000 bytes (2.1 GB, 2.0 GiB) copied, 21.2453 s, 98.7 MB/s
root@n5105-pve ➜ dd if=/dev/zero of=/mnt/wd-passport/fio.img bs=1M count=2000
2000+0 records in
2000+0 records out
2097152000 bytes (2.1 GB, 2.0 GiB) copied, 21.7685 s, 96.3 MB/s
root@n5105-pve ➜ dd if=/dev/zero of=/mnt/wd-passport/fio.img bs=1M count=2000 oflag=direct
2000+0 records in
2000+0 records out
2097152000 bytes (2.1 GB, 2.0 GiB) copied, 20.9127 s, 100 MB/s
fio¶
To benchmark persistent disk performance, use Flexible I/O tester (FIO) instead of other disk benchmarking tools such as
dd. By default,dduses a very low I/O queue depth, so it is difficult to ensure that the benchmark is generating a sufficient number of I/Os and bytes to accurately test disk performance.
- I/O type
- direct, buffered, atomic. : O_DIRECT, O_ATOMIC
- readwrite=str, rw=str
- read: Sequential reads.
- write: Sequential writes.
- randread: Random reads.
- randwrite: Random writes.
- rw,readwrite: Sequential mixed reads and writes
- randrw: Random mixed reads and writes.
- trim, randtrim, trimwrite
- Block size
- bs: The block size in bytes used for I/O units
- Buffer and Memory
- sync=str
- sync: Use synchronous file IO. O_SYNC
- dsync: Use synchronous data IO. For the majority of I/O engines, this means using O_DSYNC.
- sync=str
- I/O size
- size: The total size of file I/O for each thread of this job. Fio will run until this many bytes has been transferred, unless runtime is limited by other options (such as runtime, for instance, or increased/decreased by io_size).
- I/O engine
- ioengine=str
- psync: Basic pread(2) or pwrite(2) I/O. Default on all supported operating systems except for Windows
- libaio: Linux native asynchronous I/O. Note that Linux may only support queued behavior with non-buffered I/O (set direct=1 or buffer=0). This engine defines engine specific options.
- ioengine=str
- I/O depth
- iodepth=int
- Number of I/O units to keep in flight against the file. Note that increasing iodepth beyond 1 will not affect synchronous ioengines (except for small degrees when verify_async is in use). Even async engines may impose OS restrictions causing the desired depth not to be achieved. This may happen on Linux when using libaio and not setting
direct=1', since buffered I/O is not async on that OS. Keep an eyeon the I/O depth distribution in the fio output to verify that the achieved depth is as expected. Default: 1.
- Number of I/O units to keep in flight against the file. Note that increasing iodepth beyond 1 will not affect synchronous ioengines (except for small degrees when verify_async is in use). Even async engines may impose OS restrictions causing the desired depth not to be achieved. This may happen on Linux when using libaio and not setting
- iodepth=int
- chatgpt4:
- 当
iodepth大于 1 时,fio会尝试同时发起多个 I/O 请求,以此来模拟并发 I/O 负载。这对于评估存储系统在高并发场景下的性能非常有用。 - 对于同步 I/O 引擎(如
psync),iodepth大于 1 的设置影响不大,因为同步 I/O 操作会按顺序一个接一个地执行。但是,在使用verify_async选项时,即使是同步引擎,将iodepth设置得稍微大于 1 也可能有轻微的影响。 - 对于异步 I/O 引擎(如
libaio),增加iodepth可以显著提高并发度和吞吐量。然而,操作系统和其它因素可能限制实际达到的深度,特别是在不使用直接 I/O(direct=1)的情况下。在 Linux 中,如果不设置direct=1,libaio使用的是缓冲 I/O,而这在 Linux 上并不是异步的。 fio输出中的 I/O 深度分布可以帮助你验证实际达到的深度是否符合预期。
- 当
stonewall
wait_for_previous Wait for preceding jobs in the job file to exit, before starting this one. Can be used to insert serialization points in the job file. A stone wall also implies starting a new reporting group, see group_reporting. Optionally you can use stonewall=0 to disable or stonewall=1 to enable it.
配置文件¶
- global 公共部分,影响后面每一个 job
- 默认 job 是并行的,需要添加 stonewall等待前面一个完成
- filename 指定共同使用一个文件(否则会根据 job 名自动生成)
sudo fio --directory=/root/ --filename=test.bin ssd-win-likely.fio
vim ssd-win-likely.fio #模仿windows下diskmark,测顺序读写和4k随机
[global]
ioengine=libaio
size=10g
direct=1
runtime=60
[seq-read-4m]
bs=4M
iodepth=32
rw=read
stonewall
[seq-write-4m]
bs=4M
iodepth=32
rw=write
stonewall
[rand-read-4k]
bs=4k
iodepth=4
rw=randread
stonewall
[rand-write-4k]
bs=4k
iodepth=4
rw=randwrite
stonewall
机械硬盘例子¶
- dd read 时需要添加-iflag=direct,否则测得速度 11GB/s
- O_DIRECT:绕过系统的页缓存,更准确地衡量磁盘本身的性能(
- 顺序读时,测试/dev/sda1 和 test.img 速度是不同的 120 -> 170 MB/s
- iodepth 影响 1 -> 8: 155 -> 180 MB/s
- 在我测试的机械硬盘上,增加 jobnums 提升没有 iodepth 明显
fio --filename=/dev/sda1 --bs=1M --direct=1 --iodepth=8 --numjobs 1 --group_reporting --size=1g --runtime=60 --name SeqRead --rw=read --ioengine=libaio --readonly
SeqRead: (g=0): rw=read, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=libaio, iodepth=8
fio-3.33
Starting 1 process
Jobs: 1 (f=1): [R(1)][100.0%][r=166MiB/s][r=166 IOPS][eta 00m:00s]
SeqRead: (groupid=0, jobs=1): err= 0: pid=884774: Wed Mar 13 17:09:47 2024
read: IOPS=168, BW=168MiB/s (177MB/s)(1024MiB/6078msec)
slat (usec): min=28, max=339, avg=46.65, stdev=27.34
clat (msec): min=30, max=240, avg=45.46, stdev=25.37
lat (msec): min=30, max=240, avg=45.51, stdev=25.37
clat percentiles (msec):
| 1.00th=[ 40], 5.00th=[ 40], 10.00th=[ 40], 20.00th=[ 40],
| 30.00th=[ 40], 40.00th=[ 40], 50.00th=[ 42], 60.00th=[ 43],
| 70.00th=[ 43], 80.00th=[ 45], 90.00th=[ 45], 95.00th=[ 46],
| 99.00th=[ 234], 99.50th=[ 241], 99.90th=[ 241], 99.95th=[ 241],
| 99.99th=[ 241]
bw ( KiB/s): min=88064, max=202752, per=99.72%, avg=172032.00, stdev=40726.61, samples=12
iops : min= 86, max= 198, avg=168.00, stdev=39.77, samples=12
lat (msec) : 50=96.09%, 100=1.56%, 250=2.34%
cpu : usr=0.20%, sys=4.67%, ctx=1444, majf=0, minf=2059
IO depths : 1=0.1%, 2=0.2%, 4=0.4%, 8=99.3%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=99.9%, 8=0.1%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=1024,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=8
Run status group 0 (all jobs):
READ: bw=168MiB/s (177MB/s), 168MiB/s-168MiB/s (177MB/s-177MB/s), io=1024MiB (1074MB), run=6078-6078msec
Disk stats (read/write):
sda: ios=2108/1, merge=4/0, ticks=106583/0, in_queue=106584, util=95.24%
例子¶
aigo P7000Z 2TB pcie 4.0 (标称读 7350, 写 6750 MB/s) 输出
单独分区
root@ryzen-pve ➜ fio fio --filename=/dev/nvme0n1p5 ssd-win-likely.fio
Run status group 0 (all jobs):
READ: bw=7043MiB/s (7385MB/s), 7043MiB/s-7043MiB/s (7385MB/s-7385MB/s), io=10.0GiB (10.7GB), run=1454-1454msec
Run status group 1 (all jobs):
WRITE: bw=6392MiB/s (6703MB/s), 6392MiB/s-6392MiB/s (6703MB/s-6703MB/s), io=10.0GiB (10.7GB), run=1602-1602msec
Run status group 2 (all jobs):
READ: bw=344MiB/s (361MB/s), 344MiB/s-344MiB/s (361MB/s-361MB/s), io=2048MiB (2147MB), run=5950-5950msec
Run status group 3 (all jobs):
WRITE: bw=818MiB/s (857MB/s), 818MiB/s-818MiB/s (857MB/s-857MB/s), io=2048MiB (2147MB), run=2505-2505msec
Run status group 4 (all jobs):
WRITE: bw=502MiB/s (526MB/s), 502MiB/s-502MiB/s (526MB/s-526MB/s), io=2048MiB (2147MB), run=4082-4082msec
Disk stats (read/write):
nvme0n1: ios=544852/1011542, merge=0/0, ticks=373885/471120, in_queue=845097, util=91.87%
zfs dataset, compression=off
root@ryzen-pve ➜ fio fio --filename=/pool0/test/fio.img ssd-win-likely.fio
Run status group 0 (all jobs):
READ: bw=2201MiB/s (2308MB/s), 2201MiB/s-2201MiB/s (2308MB/s-2308MB/s), io=10.0GiB (10.7GB), run=4653-4653msec
Run status group 1 (all jobs):
WRITE: bw=2786MiB/s (2921MB/s), 2786MiB/s-2786MiB/s (2921MB/s-2921MB/s), io=10.0GiB (10.7GB), run=3676-3676msec
Run status group 2 (all jobs):
READ: bw=174MiB/s (183MB/s), 174MiB/s-174MiB/s (183MB/s-183MB/s), io=2048MiB (2147MB), run=11739-11739msec
Run status group 3 (all jobs):
WRITE: bw=165MiB/s (173MB/s), 165MiB/s-165MiB/s (173MB/s-173MB/s), io=2048MiB (2147MB), run=12393-12393msec
Run status group 4 (all jobs):
WRITE: bw=194MiB/s (204MB/s), 194MiB/s-194MiB/s (204MB/s-204MB/s), io=2048MiB (2147MB), run=10530-10530msec
samsung pm9a1 zfs dataset compression=off
root@ryzen-pve ➜ fio fio --filename=/rpool/test/fio.img ssd-win-likely.fio
s
Run status group 0 (all jobs):
READ: bw=2485MiB/s (2606MB/s), 2485MiB/s-2485MiB/s (2606MB/s-2606MB/s), io=10.0GiB (10.7GB), run=4121-4121msec
Run status group 1 (all jobs):
WRITE: bw=2683MiB/s (2813MB/s), 2683MiB/s-2683MiB/s (2813MB/s-2813MB/s), io=10.0GiB (10.7GB), run=3817-3817msec
Run status group 2 (all jobs):
READ: bw=171MiB/s (179MB/s), 171MiB/s-171MiB/s (179MB/s-179MB/s), io=2048MiB (2147MB), run=12004-12004msec
Run status group 3 (all jobs):
WRITE: bw=207MiB/s (217MB/s), 207MiB/s-207MiB/s (217MB/s-217MB/s), io=2048MiB (2147MB), run=9897-9897msec
Run status group 4 (all jobs):
WRITE: bw=243MiB/s (254MB/s), 243MiB/s-243MiB/s (254MB/s-254MB/s), io=2048MiB (2147MB), run=8439-8439msec
网络¶
network 相关¶
常见网络配置方法¶
NetworkConfiguration - Debian Wiki
- ifupdown
- debian 默认的方法
- 配置文件为:
/etc/network/interfaces - ifupdown2 是新版,支持更加灵活的配置
- NetworkManger
- 目标是尽可能保证连接到网络。使用自动的规则配置网络,比如检测到有线设备就会连接
- 常用于桌面发行版
- 可以使用命令行工具 nmcli 进行配置,也可以使用 TUI 工具 nmtui 进行配置。
- systemd
- 相关的服务:systemd-networkd, systemd-resolved
- 配置文件位于
/etc/system/network,使用类似于 ini 格式
- netplan
- 常见于 ubuntu,底层可以基于 systemd-networkd 或 NetworkManager(服务器版和桌面版)
- 是另一层抽象,使用自己的配置文件
/etc/netplan/,使用 yaml 格式。
dns 配置方法¶
- 需要区分:有些工具是在本地运行一个 dns 服务器,监听 53 请求。这种可以实现 local dns caching 等功能。
- 有些工具只是修改
/etc/resolve.conf(通常不直接修改,而是替换该文件为一个软连接)为上游 dns。 - 有哪些 dns server
- dnsmasq
- systemd-resolved
- NetworkManger 本身不提供 dns 能力,可以配置使用不同后端:
- default(修改 resolve.conf 包含(所有接口?)上游 dns
- dnsmasq 和 systemd-resolved
dnsmasq¶
openwrt 上比较熟悉
dns 配置方法 —— systemd-resolved¶
systemd-resolved - ArchWiki (archlinux.org)
systemd-resolved has four different modes for handling the file—stub, static, uplink and foreign
设置上游 DNS¶
自动¶
systemd-resolved will work out of the box with a network manager using /etc/resolv.conf. No particular configuration is required since systemd-resolved will be detected by following the /etc/resolv.conf symlink. This is going to be the case with systemd-networkd, NetworkManager, and iwd.
手动¶
/etc/systemd/resolved.conf.d/dns_servers.conf
[Resolve]
DNS=192.168.35.1 fd7b:d0bd:7a6e::1
Domains=~.
fallbak¶
没有 DNS 时,fallbak 到 Cloudflare, Quad9 and Google.
正常情况/etc/resolv.conf为软连接,内容为
手动修复
网络工具¶
Chapter 5. Network setup (debian.org)
- iproute2
- iptables
- ethtool
- mtr
- nmap
- tcpdump
- dnsutils: nslookup, dig
dhcp¶
测试 dhcp 是否工作
- netplan(或者重启容器) + tcpdump + wireshark
- -d: debug 模式,前台运行
- -n: 不设置接口
- -s: 指定 dhcp server(否则是广播)
- -w: 没有找到广播接口时也不退出,用于可插拔网卡。
接口放在前面
dns¶
dig¶
- @ 指定 DNS 查询使用的服务器名称或 IP,IP 地址可以是用点分隔的 IPv4 地址也可以是冒号分隔的 IPv6 地址。当参数指定的值是服务器的主机名时,dig 命令会在查询该域名服务器前先解析该主机名;
- -p 指定 DNS 查询使用的端口号,默认情况下 DNS 查询使用标准的 53 端口,若使用非端口则需要通过 -p 参数指定,可使用此选项来测试已配置为侦听非标准端口号上的 DNS 服务器;
- -t 指定 DNS 查询的记录类型,常用的类型包括:A/AAAA/NS/MX/CNAME 等,缺省查询类型是 A;
- -4 指定 dig 命令仅使用 IPv4 查询传输;
- -6 指定 dig 命令仅使用 IPv6 查询传输;
- +trace 跟踪从根名称服务器开始的迭代查询过程,缺省情况不使用跟踪。启用跟踪时,dig 命令会执行迭代查询以解析要查询的名称,显示来自用于解析查询的每个服务器的应答。
指定解析类型
- NS 记录:用来指定域名由哪个 DNS 服务器进行解析;
- CNAME 记录:用来定义域名的别名,方便实现将多个域名解析到同一个 IP 地址;
- A 记录:用来指定主机名对应的 IPv4 地址;
- AAAA 记录:用来指定主机名对应的 IPv6 地址;
- MX 记录:用来指定收件人域名的邮件服务器,SMTP 协议会根据 MX 记录的值来决定邮件的路由过程;
- PTR 记录:常用于反向地址解析,将 IP 地址解析到对应的名称;
- SOA 记录:称为起始授权机构记录,不同于 NS 记录用于标识多台域名解析服务器,SOA 记录用于在多台 NS 记录中哪一台是主 DNS 服务器。
USTC lug 加群链接
dig jointele.ustclug.org TXT
;; ANSWER SECTION:
jointele.ustclug.org. 600 IN TXT "(base64) aHR0cHM6Ly90Lm1lLytYOXg1V09qTVpVbGlZVGRs"
查看上游 dns¶
有多种 dns 设置方式:
- 直接编辑/etc/resolve 设置上游 dns
- systemd-resolve 服务(自动设置 dns)
从 ubuntu22.04 开始
systemd-resolve command not found in Ubuntu 22.04 desktop - Ask Ubuntu
iptables¶
持久化
iptables-save > /etc/iptables/rules.v4 #
ip6tables-save > /etc/iptables/rules.v6
iptables-restore < /etc/iptables/rules.v4
安装 iptabels-persistent
遇到的问题¶
bridge iptable 不生效¶
bridge-nf-call-iptables - BOOLEAN
1 : pass bridged IPv4 traffic to iptables' chains.
0 : disable this.
Default: 1
系统维护¶
initrd¶
ubuntu22.04 intird 69M,全部都是微码。
EFI 分区只有 grub.efi 和 grub 配置
root@ryzen ➜ EFI tree -L 2 ubuntu
ubuntu
├── BOOTX64.CSV
├── grub.cfg
├── grubx64.efi
├── mmx64.efi
└── shimx64.efi
search.fs_uuid ff2e2d36-0788-436f-9d42-e390f318f0ec root hd0,gpt3
set prefix=($root)'/boot/grub'
configfile $prefix/grub.cfg
pve initrd 59M,包含了 /etc/, /usr/bin, /usr/lib/firmware, /usr/lib/modules/***.ko
pve EFI 分区包含了 initrd, vmlinuz
root@ryzen-pve ➜ ~ l /boot/efi/EFI/proxmox/6.8.12-2-pve/
total 73M
-rwxr-xr-x 1 root root 59M Jan 22 14:28 initrd.img-6.8.12-2-pve
-rwxr-xr-x 1 root root 14M Sep 5 18:03 vmlinuz-6.8.12-2-pve
还包含一个 loader 目录(没有使用 grub)
root@ryzen-pve ➜ ~ tree -L 3 /boot/efi/loader
/boot/efi/loader
├── entries
│ ├── proxmox-6.5.13-6-pve.conf
│ ├── proxmox-6.8.12-2-pve.conf
│ └── proxmox-6.8.4-3-pve.conf
├── entries.srel
├── loader.conf
└── random-seed
# proxmox-xxx.conf 内容
title Proxmox Virtual Environment
version 6.8.12-2-pve
options root=ZFS=rpool/ROOT/pve-1 boot=zfs amd_iommu=on iommu=pt pcie_acs_override=multifunction mitigations=off
linux /EFI/proxmox/6.8.12-2-pve/vmlinuz-6.8.12-2-pve
initrd /EFI/proxmox/6.8.12-2-pve/initrd.img-6.8.12-2-pve
ubuntu 启动时,grub 启动后,挂载
使用 lsinitrd 查看¶
root@ryzen ➜ /boot lsinitrd /boot/initrd.img-$(uname -r)
Image: /boot/initrd.img-6.8.0-49-generic: 69M
========================================================================
Early CPIO image
========================================================================
drwxr-xr-x 3 root root 0 Dec 18 2019 .
drwxr-xr-x 3 root root 0 Dec 18 2019 kernel
drwxr-xr-x 3 root root 0 Dec 18 2019 kernel/x86
drwxr-xr-x 2 root root 0 Dec 18 2019 kernel/x86/microcode
-rw-r--r-- 1 root root 76166 Dec 18 2019 kernel/x86/microcode/AuthenticAMD.bin
========================================================================
Version:
Arguments:
dracut modules:
========================================================================
drwxr-xr-x 2 root root 0 Aug 29 20:00 kernel
drwxr-xr-x 2 root root 0 Aug 29 20:00 kernel/x86
drwxr-xr-x 2 root root 0 Aug 29 20:00 kernel/x86/microcode
drwxr-xr-x 2 root root 0 Aug 29 20:00 kernel/x86/microcode/.enuineIntel.align.0123456789abc
-rw-r--r-- 1 root root 7979008 Aug 29 20:00 kernel/x86/microcode/GenuineIntel.bin
========================================================================
解压查看¶
initrd.img 通常是一个压缩后的 cpio archive。
- 先用 file 查看文件类型,然后解压,再输入给 cpio 提取
- unzstd -c 表示解压到标准输出
- cpio -D 解压到指定路径
gzip compressed dataXZ compressed dataLZMA compressed dataASCII cpio archive(This is rare for modern initrds)
bash 配置¶
1. 登录 Shell (Login Shell)
登录 shell 的加载顺序如下:
- /etc/profile:系统级的全局配置文件,对所有用户生效。通常包含系统环境变量的设置、启动程序的脚本等。
- /etc/profile.d/*.sh:
/etc/profile.d目录下的所有.sh文件,也是系统级的全局配置,方便管理员添加自定义的配置脚本。 - ~/.bash_profile:用户的个人配置文件,仅对当前用户生效。如果该文件存在,则执行该文件,后面的文件不再执行。
- ~/.bash_login:如果
~/.bash_profile不存在,则执行该文件。 - ~/.profile:如果
~/.bash_profile和~/.bash_login都不存在,则执行该文件。 - ~/.bash_logout:在退出登录 shell 时执行的文件,用于执行一些清理工作。
非登录 shell 的加载顺序较为简单:
- /etc/bashrc:系统级的全局配置文件,对所有非登录 shell 生效。
- ~/.bashrc:用户的个人配置文件,仅对当前用户的非登录 shell 生效。
sudoer 设置¶
将用户添加到 admin 或 sudo 用户组即可
免密码:
sudoers 每项含义(待续)
sshd 设置¶
允许 ssh 登录 root
先改为 yes,然后 ssh-copy-id 后,改为禁用密码
禁用密码登录
其它选项
PermitRootLogin prohibit-password
PubkeyAuthentication yes # 允许公钥登录
PubkeyAcceptedKeyTypes=+ssh-rsa
PasswordAuthentication no # 禁用密码登录
ChallengeResponseAuthentication no
Accepted password for yfy from 192.168.36.215 port 50342 ssh2
Accepted publickey for yfy from 192.168.36.180 port 26464 ssh2: RSA SHA256:z9yheNzateaIikTVkTXN1lmMPRIsp+H0ssbhU4Q8Kfg
pam_unix(sshd:session): session opened for user yfy(uid=1000) by (uid=0)
setcap¶
授予特定二进制文件在不提升用户权限的情况下绑定低端口
➜ ~ sudo setcap cap_sys_admin+p $(readlink -f $(which sunshine))
➜ ~ echo $(readlink -f $(which sunshine))
/usr/bin/sunshine-v0.23.1
➜ ~ getcap /usr/bin/sunshine-v0.23.1
/usr/bin/sunshine-v0.23.1 cap_sys_admin=p
ldap¶
LDAP - ACSA Docs (acsalab.com)
systemd¶
ssh 证书¶
SSH Certificate Authority - LUG @ USTC (ustclug.org) Managing servers with OpenSSH Certificate Authority - iBug
- client 验证 server 身份,需要将 server 公钥添加到 known_hosts 中。
- 当有多个服务器时,client 需要同意多次(ssh 时的 yes)
- 当 server 公钥变更时,还得修改 known_hosts
- server 验证 client 身份,同样需要将 client public key 添加到 authorized_keys 中。
- 多个服务端和客户端,需要将每个 client 公钥复制到每个 server。
- 修改一个 client 需要修改所有 server
SSH CA(Certificate Authority) 是一对受信任的密钥,用于签发证书。
An SSH Certificate Authority (CA) is a trusted key pair that issues certificates.
签发的证书可以用来授权 client 或者 server。(通过信任 host CA,client 可以信任所有 server,只要它们有 host CA 签名的证书。同样,通过信任 user CA,server 可以信任所有的 client,只要它们有 user CA 签名的证书。)
Certificates can be used for authentication on both the server side and the client side
SSH CA 和 X.509 证书系统不同的是,证书无法签发新的证书(即无法嵌套)
host CA 和 user CA 可以是不同的,也可以是相同的。
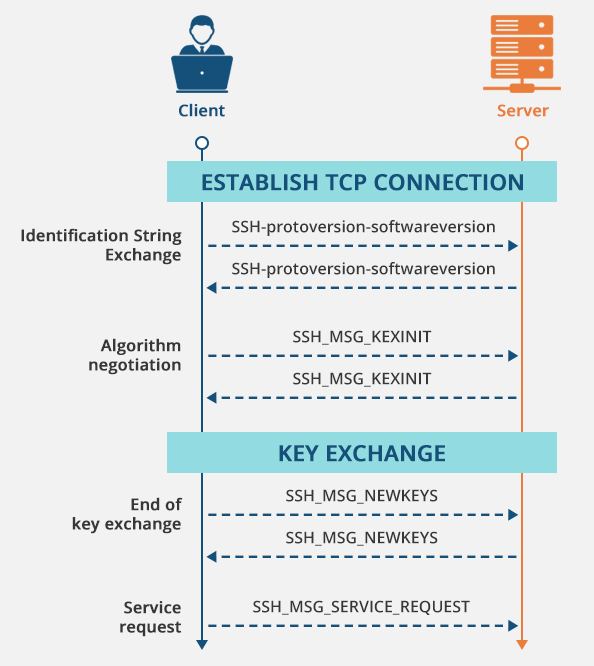
SSH CA¶
创建 CA¶
和创建一个通常的密钥对一样。
- -t dsa | ecdsa | ecdsa-sk | ed25519 | ed25519-sk | rsa
- -C comment:添加到公钥结尾
签发证书¶
ssh-keygen -s /path/to/ssh_ca \
-I certificate_identity \
-n principals \
[-O options] \
[-V validity_interval] \
public_key_file
使用 host CA 授权 server 端¶
给 server 的公钥 ssh_host_rsa_key.pub 签名
ssh-keygen -s /path/to/ssh_ca \
-I blog \
-h \
-n blog.s.ustclug.org,blog.p.ustclug.org,10.254.0.15,202.141.176.98,202.141.160.98 \
ssh_host_rsa_key.pub
- -h 表示签发的是 host 证书(server 端)
- -n 用于限制该证书只在提供的域名或者 ip 上有效。这样即使该证书被偷了,偷窃者也无法伪造我们的服务器。
添加到 sshd 配置中,这样 client 连接时会尝试提供该证书
客户端信任 CA 机构
- 将 CA 公钥保存在 my_ca.pub 中
- 保存在 dns 中
- 利用{command1 && command2 }将两条命令合并,将其输出重定向
{printf "@cert-authority * " && dig ca.yfycloud.top TXT +noall +answer | awk -F'TXT' '{print $NF}' |xargs} >> ~/.ssh/known_hosts
使用 nslookup(windows bash 下测试)
(printf "@cert-authority * " && nslookup -q=txt ca.yfycloud.top |grep CA | xargs) >> ~/.ssh/known_hosts
使用 user CA 授权 client 端¶
服务端信任 user CA
给指定用户签发证书
- 将生成的 id_rsa-cert.pub 放至 id_rsa.pub 同一目录,ssh 连接服务端时会自动读取。
- -n 用于限制允许登录的用户
遇到问题¶
mobaxterm连接服务器时报错:No supported authentication methods available (server sent: publickey)
但是我明明是指定的使用ssh key登录,在命令行中也确实是能够用指定的私钥登录的。
后面发现问题是mobaxterm发现了我有一个证书,使用该证书去登录了。但是该证书签名时只principal只指定了root,从而导致登不上。 服务端日志如下,刚开始指定登录root成功,第二次指定fyyuan登录失败
Mar 29 11:39:26 snode1 sshd[1143073]: Accepted publickey for root from 2001:da8:d800:c017:ed94:1e42:a843:27f9 port 23902 ssh2: ED25519-CERT SHA256:oL5HVEHu4AQj4e0d03kjT39A6p5t+3j5SKUKOqLKjwI ID Yuan Fuyan (serial 0) CA ECDSA SHA256:e/hc4wrIaub3Q8UGmQYQI3A2fiiHF/RevFKo0UCG4Tc
Mar 29 11:39:26 snode1 sshd[1143073]: pam_unix(sshd:session): session opened for user root by (uid=0)
Mar 29 11:39:45 snode1 sshd[1144083]: error: Certificate invalid: name is not a listed principal
Mar 29 11:39:45 snode1 sshd[1144083]: error: Received disconnect from 2001:da8:d800:c017:ed94:1e42:a843:27f9 port 23929:14: No supported authentication methods available [preauth]
Mar 29 11:39:45 snode1 sshd[1144083]: Disconnected from authenticating user fyyuan 2001:da8:d800:c017:ed94:1e42:a843:27f9 port 23929 [preauth]
包管理器 apt¶
source.list¶
ONE-LINE-STYLE FORMAT
If options should be provided they are separated by spaces and all of them together are enclosed by square brackets ([]) included in the line after the type separated from it with a space. If an option allows multiple values these are separated from each other with a comma (,). An option name is separated from its value(s) by an equals sign (=). Multivalue options also have -= and += as separators, which instead of replacing the default with the given value(s) modify the default value(s) to remove or include the given values.
查询文件¶
linux - List of files installed from apt package - Server Fault
列出包的内容
- 已安裝包:
dpkg -L deb - 未安裝包:
apt-file list $package - 有 deb 文件:
dpkg --contents $package.deb
查询文件位于哪个包中
源优先级¶
按照 nvidia 官网下载了本地版本的 cuda deb,安装后在/var/cuda-repo-ubuntu2004-12-1-local可以看到 deb 包。但是 apt install 时仍然采用了 nvidia 仓库的。
解决方法:
- 直接注释掉
/etc/apt/source.list中的 nvidia 仓库,然后 apt update- 也有可能 source.list 中没有 developer.download.nvidia.com,那么禁用
/etc/apt/source.list.d/下的在线 cuda 仓库。如mv cuda-ubuntu2004-x86_64.list cuda-ubuntu2004-x86_64.list.bak。
- 也有可能 source.list 中没有 developer.download.nvidia.com,那么禁用
vim /etc/apt/preference.d/cuda-repository-pin-600
# Priority 越小优先级越高
Package: nsight-compute
Pin: origin *ubuntu.com*
Pin-Priority: -1
Package: nsight-systems
Pin: origin *ubuntu.com*
Pin-Priority: -1
Package: *
Pin: release l=NVIDIA CUDA
Pin-Priority: 600
➜ ~ apt-cache policy gnome-shell-extension-ubuntu-dock
gnome-shell-extension-ubuntu-dock:
Installed: (none)
Candidate: 72~ubuntu5.22.04.2.1
Version table:
72~ubuntu5.22.04.2.1 500
500 http://mirrors.ustc.edu.cn/ubuntu jammy-updates/main amd64 Packages
72~ubuntu5 500
500 http://mirrors.ustc.edu.cn/ubuntu jammy/main amd64 Packages
deb 包与软件源¶
- deb 包是 ar 文件(不支持目录,ar 格式同样用于静态链接库)
- 包含
-
debian-binary:仅包含 deb 版本号的文本文件,目前版本为2.0。 -control.tar.xz(或control.tar.zst) - control:包含软件包的元数据,例如版本,架构,维护者,依赖、描述等 - md5sum:data.tar.xz 内容的 md5sum -data.tar.xz(或data.tar.zst等):包含软件包的实际文件。
软件源目录结构:
最简单的需要包含以下部分:
- deb 包
Packages:将所有包的control文件连接起来 - 生成:dpkg-scanpackages . > PackagesRelease:软件源的元数据,包含了生成时间、Label,Origin(域名),Packages和自身文件(头部)的哈希(md5, sha1等等) - 使用apt-ftparchive生成
Debian 或 Ubuntu 官方源 更复杂,仓库的元数据会存储在 dists 目录下,而软件包则存储在 pool 目录下
Release.gpg:Release文件的 GPG 签名。InRelease:附加了 GPG 签名的Release文件。contrib/,main/,non-free/,non-free-firmware/是不同的组件(Components)
删除 i386¶
- i386 可以放心删
- apt 删除会因为删除 libc:i386 等包而报错,使用 dpkg --force-all
删除完后,可能有一些 x86 的包会依赖 i386 的包,也要删除
base) fyyuan@snode2 ➜ ~ sudo dpkg --force-all --purge $(dpkg --list | grep 'i386' | awk '{print $2}')
dpkg: warning: overriding problem because --force enabled:
dpkg: warning: this is a protected package; it should not be removed
dpkg: warning: overriding problem because --force enabled:
dpkg: warning: this is a protected package; it should not be removed
(Reading database ... 286736 files and directories currently installed.)
Removing libc6:i386 (2.35-0ubuntu3.9) ...
Purging configuration files for libc6:i386 (2.35-0ubuntu3.9) ...
dpkg: warning: overriding problem because --force enabled:
dpkg: warning: this is a protected package; it should not be removed
Removing libcrypt1:i386 (1:4.4.27-1) ...
Removing libgcc-s1:i386 (12.3.0-1ubuntu1~22.04) ...
Removing gcc-12-base:i386 (12.3.0-1ubuntu1~22.04) ...
dpkg: libc6-i386: dependency problems, but removing anyway as you requested:
libclang-common-6.0-dev depends on libc6-i386 (>= 2.17).
libclang-common-12-dev depends on libc6-i386 (>= 2.34).
libclang-common-10-dev depends on libc6-i386 (>= 2.17).
lib32stdc++6 depends on libc6-i386 (>= 2.34).
lib32gcc-s1 depends on libc6-i386 (>= 2.35).
Removing libc6-i386 (2.35-0ubuntu3.9) ...
Purging configuration files for libc6-i386 (2.35-0ubuntu3.9) ...
Processing triggers for libc-bin (2.35-0ubuntu3.9) ..
用户管理¶
A multiuser system must provide basic support for user security in three areas: identification, authentication, and authorization. The identification portion of security answers the question of who users are. The authentication piece asks users to prove that they are who they say they are. Finally, authorization is used to define and limit what users are allowed to do.
identification¶
The Linux kernel supports the traditional concept of a Unix user.
- User: A user is an entity that can run processes and own files.
- kernel only know user id, don't know username
- Groups are sets of users. The primary purpose of groups is to allow a user to share file access to other members of a group.
- adduser:交互式添加用户
- useradd 为更底层的命令
- usermod -aG sudo user:将用户添加到 sudo 组
- gpasswd -d user group: 将用户从组中删除
sticky
authentication¶
When it comes to user identification, the Linux kernel knows only the numeric user IDs for process and file ownership. The kernel knows authorization rules for how to run setuid executables and how user IDs may run the setuid() family of system calls to change from one user to another. However, the kernel doesn’t know anything about authentication: usernames, passwords, and so on. Practically everything related to authentication happens in user space.
PAM¶
To accommodate flexibility in user authentication, in 1995 Sun Microsystems proposed a new standard called Pluggable Authentication Modules (PAM), a system of shared libraries for authentication (Open Software Foundation RFC 86.0, October 1995).
You’ll normally find PAM’s application configuration files in the /etc/pam.d directory
- function type: The function that a user application asks PAM to perform
- auth: Authenticate a user (see if the user is who they say they are).)
- account
- session
- password: Change a user’s password or other credentials.
- control arguement: 可以用来表示一个流程图
- sufficient: 成功返回真,否则继续判断
- requisite: 成功继续判断、否则返回假
- required: 成功则继续判断、否则返回假并进行一次额外操作
- module
- pam_shell.so: checks to see if the user’s shell is listed in /etc/shells
- pam_unix.so: asks the user for their password and checks it
通过 man pam_ 查看各种模块作用。
禁止普通用户执行 su¶
为了方便 IPMI 登陆,root 用户没有密码。因为禁用了密码登录,因此不用担心安全。 但是为了普通用户通过 su 切换到 root 用户,需要额外设置 PAM。
启用 pam_wheel.so 即可,检查用户是否是 root group,不是则授权失败。
pam_wheel
- 作用:Only permit root access to members of group wheel
- 参数:
pam_wheel.so [debug] [deny] [group=name] [root_only] [trust]- group 参数:Instead of checking the wheel or GID 0 groups, use the name group to perform the authentication.
authorization / File permission¶
Lacking execute permission on a directory can limit the other permissions in interesting ways. For example, how can you add a new file to a directory (by leveraging the write permission) if you can't access the directory's metadata to store the information for a new, additional file? You cannot. It is for this reason that directory-type files generally offer execute permission to one or more of the user owner, group owner, or others.
日志/journalctl¶
How To Use Journalctl to View and Manipulate Systemd Logs | DigitalOcean
journalctl --list-boots
journalctl -b # 自上次reboot开始log
journalctl -b -1 # 上一次reboot
journalctl --since "2015-01-10" --until "2015-01-11 03:00" # YYYY-MM-DD HH:MM:SS
journalctl --since yesterday
journalctl -S yesterday
journalctl -k # 内核
sytemd.time(7)¶
time span¶
Time spans refer to time durations
• usec, us, µs
• msec, ms
• seconds, second, sec, s
• minutes, minute, min, m
• hours, hour, hr, h
• days, day, d
• weeks, week, w
• months, month, M (defined as 30.44 days)
• years, year, y (defined as 365.25 days)
example
timestamp¶
Timestamps refer to specific, unique points in time
一般显示格式:Fri 2012-11-23 23:02:15 CET
包含毫秒格式(sub-second remainder is expected separated by a full stop from the seconds component.)
2014-03-25 03:59:56.654563
特殊关键字:"now", "today", "yesterday", and "tomorrow"
相对时间,- 表示当前时间减去 timespan,+ 则是加上。也可以在结尾使用 ago 和 left(注意需要一个空格)
+3h30min → Fri 2012-11-23 21:45:22
@ 表示相对于 UNIX epoch
Finally, a timespan prefixed with "@" is evaluated relative to the UNIX time epoch 1st Jan, 1970, 00:00.
@1395716396 → Tue 2014-03-25 03:59:56
Fri 2012-11-23 11:12:13 → Fri 2012-11-23 11:12:13
2012-11-23 11:12:13 → Fri 2012-11-23 11:12:13
2012-11-23 11:12:13 UTC → Fri 2012-11-23 19:12:13
2012-11-23 → Fri 2012-11-23 00:00:00
12-11-23 → Fri 2012-11-23 00:00:00
11:12:13 → Fri 2012-11-23 11:12:13
11:12 → Fri 2012-11-23 11:12:00
now → Fri 2012-11-23 18:15:22
today → Fri 2012-11-23 00:00:00
today UTC → Fri 2012-11-23 16:00:00
yesterday → Fri 2012-11-22 00:00:00
tomorrow → Fri 2012-11-24 00:00:00
tomorrow Pacific/Auckland → Thu 2012-11-23 19:00:00
+3h30min → Fri 2012-11-23 21:45:22
-5s → Fri 2012-11-23 18:15:17
11min ago → Fri 2012-11-23 18:04:22
@1395716396 → Tue 2014-03-25 03:59:56
➜ ~ systemd-analyze timestamp now
Original form: now
Normalized form: Mon 2024-06-03 18:09:45 CST
(in UTC): Mon 2024-06-03 10:09:45 UTC
UNIX seconds: @1717409385.708355
From now: 165us ago
calendar event¶
Calendar events may be used to refer to one or more points in time in a single expression. They form a superset of the absolute timestamps explained above
格式和 timestamps 类似
Thu,Fri 2012-*-1,5 11:12:13
规则
*表示通配符,逗号分隔表示多个值..表示连续的一段值- 省略 date 表示今天,省略 time 表示 00:00:00
start/repetition:从 start 开始,增加 repetition 的倍数的所有值。- date 中可以使用
~表示倒数的第几天。如*-02~01表示 2 月最后一天。"Mon *-05~07/1"means "the last Monday in May."。~07/1 表示从最后一周开始的每一天,mon 则限制了周一。
一些规则的简写
minutely → *-*-* *:*:00
hourly → *-*-* *:00:00
daily → *-*-* 00:00:00
monthly → *-*-01 00:00:00
weekly → Mon *-*-* 00:00:00
yearly → *-01-01 00:00:00
quarterly → *-01,04,07,10-01 00:00:00
semiannually → *-01,07-01 00:00:00
示例
Sat,Thu,Mon..Wed,Sat..Sun → Mon..Thu,Sat,Sun *-*-* 00:00:00
Mon,Sun 12-*-* 2,1:23 → Mon,Sun 2012-*-* 01,02:23:00
Wed *-1 → Wed *-*-01 00:00:00
Wed..Wed,Wed *-1 → Wed *-*-01 00:00:00
Wed, 17:48 → Wed *-*-* 17:48:00
Wed..Sat,Tue 12-10-15 1:2:3 → Tue..Sat 2012-10-15 01:02:03
*-*-7 0:0:0 → *-*-07 00:00:00
10-15 → *-10-15 00:00:00
monday *-12-* 17:00 → Mon *-12-* 17:00:00
Mon,Fri *-*-3,1,2 *:30:45 → Mon,Fri *-*-01,02,03 *:30:45
12,14,13,12:20,10,30 → *-*-* 12,13,14:10,20,30:00
12..14:10,20,30 → *-*-* 12..14:10,20,30:00
mon,fri *-1/2-1,3 *:30:45 → Mon,Fri *-01/2-01,03 *:30:45
03-05 08:05:40 → *-03-05 08:05:40
08:05:40 → *-*-* 08:05:40
05:40 → *-*-* 05:40:00
Sat,Sun 12-05 08:05:40 → Sat,Sun *-12-05 08:05:40
Sat,Sun 08:05:40 → Sat,Sun *-*-* 08:05:40
2003-03-05 05:40 → 2003-03-05 05:40:00
05:40:23.4200004/3.1700005 → *-*-* 05:40:23.420000/3.170001
2003-02..04-05 → 2003-02..04-05 00:00:00
2003-03-05 05:40 UTC → 2003-03-05 05:40:00 UTC
2003-03-05 → 2003-03-05 00:00:00
03-05 → *-03-05 00:00:00
hourly → *-*-* *:00:00
daily → *-*-* 00:00:00
daily UTC → *-*-* 00:00:00 UTC
monthly → *-*-01 00:00:00
weekly → Mon *-*-* 00:00:00
weekly Pacific/Auckland → Mon *-*-* 00:00:00 Pacific/Auckland
yearly → *-01-01 00:00:00
annually → *-01-01 00:00:00
*:2/3 → *-*-* *:02/3:00
日志文件¶
/run/log/journal/MACHINE-ID/:存储在内存中,重启消失/var/log/journal/MACHINE-ID:存储在磁盘中
查看大小:

清除:
- vacuum:删除归档的日志(不会删除 active 的)
- rotate:将 active 归档。可以合并到上条命令
journalctl --rotate
journalctl --vacuum-time=1months # 一个月以前的旧日志。格式:1m, 2h, 2weeks, 4months
journalctl --vacuum-size=100M # 只保留新的100M大小的日志
设置最大日志大小:
SystemMaxUse=, RuntimeMaxUse=
Enforce size limits on the journal files stored. The options prefixed with "System" apply to the journal files when stored on a persistent file system, more specifically /var/log/journal. The options prefixed with "Runtime" apply to the journal files when stored on a volatile in-memory file system, more specifically /run/log/journal.
MaxFileSec=
The maximum time to store entries in a single journal file before rotating to the next one.
查看重启原因¶
https://unix.stackexchange.com/a/278166
- 正常顺序:
- reboot 没有对应的 shutdown 表示非正常关机
shutdown system down ... <-- first the system shuts down
reboot system boot ... <-- afterwards the system boots
runlevel (to lvl 3) # runlevel3表示无图形界面,开机桌面环境可能是runlevel 5
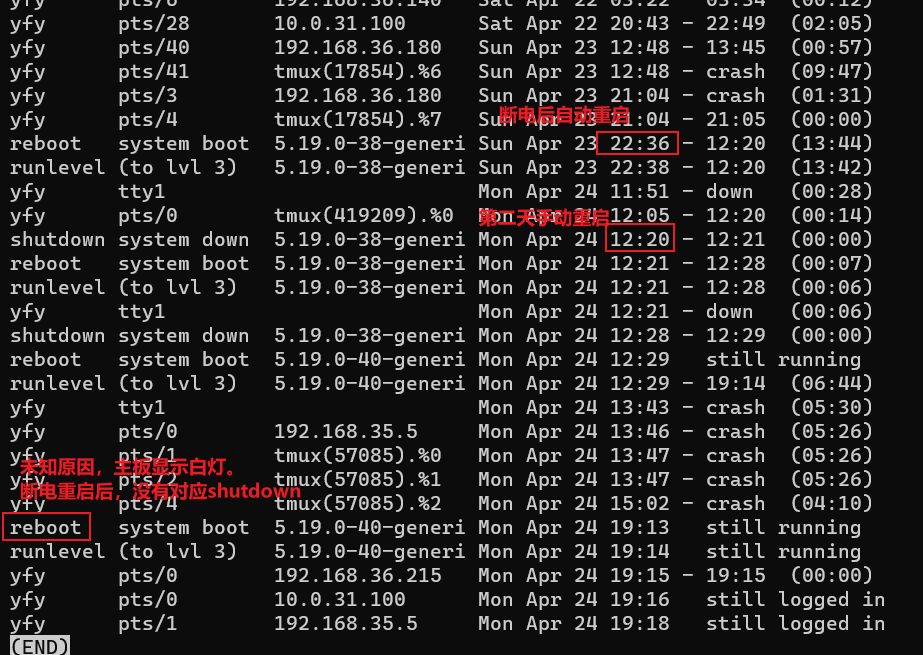
查看 crontab 日志¶
更换内核¶
编译¶
8.10. Compiling a Kernel (debian-handbook.info)
disabling the debug information¶
$ make deb-pkg LOCALVERSION=-falcot KDEB_PKGVERSION=$(make kernelversion)-1
[...]
$ ls ../*.deb
../linux-headers-5.10.46-falcot_5.10.46-1_amd64.deb
../linux-image-5.10.46-falcot_5.10.46-1_amd64.deb
../linux-image-5.10.46-falcot-dbg_5.10.46-1_amd64.deb
../linux-libc-dev_5.10.46-1_amd64.deb
The whole process requires around 20 GB of free space, at least 8 GB of RAM, and several hours of compilation (utilizing one core) for a standard amd64 Debian kernel. These requirements can be drastically reduced by disabling the debug information using
CONFIG_DEBUG_INFO=n, but this will make it impossible to trace kernel errors (“oops”) usinggdband also stop the creation of the linux-image-version-dbg package.
# 获得当前官方kernel编译配置,如/boot/config-5.19.0-35-generic
kernel_config=$(ls /boot/config-* | grep generic | sort -Vr | head -n 1)
cp "${kernel_config}" .config
# 基于当前.confg,只询问新内核中新功能的配置
make oldconfig
# 编译
make -j "$(nproc)" bindeb-pkg LOCALVERSION="${kernel_localversion}" || exit
# 安装
sudo dpkg -i ../linux-image-${kernel_version}${kernel_localversion}*.deb ../linux-headers-${kernel_version}${kernel_localversion}*.deb
# 更新grub,通过GRUB_DEFAULT选择编译的内核
vim /etc/default/grub
grub_line="GRUB_DEFAULT=\"Advanced options for Ubuntu>Ubuntu, with Linux ${kernel_version}${kernel_localversion}\""
sudo sed -i -e "s/^#GRUB_DEFAULT=.*/\0\n${grub_line}/" "${grub_config}"
sudo update-grub
missing certificate¶
Building a custom kernel based on these settings will fail if
debian/certs/debian-uefi-certs.pemdoes not exist. This file can either be obtained from the kernel team's Git repository and placed into the source tree, or it can be replaced by your own certificate(s), or you'll have to disable the setting viaCONFIG_SYSTEM_TRUSTED_KEYS="".
sed -i -e '/^CONFIG_SYSTEM_TRUSTED_KEYS=/ c\CONFIG_SYSTEM_TRUSTED_KEYS=\"\"' .config
sed -i -e '/^CONFIG_SYSTEM_REVOCATION_KEYS=/ c\CONFIG_SYSTEM_REVOCATION_KEY=\"\"' .config
dkms¶
使用 patched kernel 后,没有了 zfs,无法启动 lxc。 Ubuntu 20.04, building patched kernel results in no ZFS support - Ask Ubuntu
https://debian-handbook.info/browse/stable/sect.kernel-compilation.html#sect.modules-build
- 一些模块不能打包到 linux 内核中
- 使用 dkms 自动化编译这些模块。需要安装了对应的
linux-headers-*
Compiling External Modules Some modules are maintained outside of the official Linux kernel. To use them, they must be compiled alongside the matching kernel. While we could manually extract the tarball and build the module, in practice we prefer to automate all this using the DKMS framework (Dynamic Kernel Module Support). Most modules offer the required DKMS integration in a package ending with a
-dkmssuffix. In our case, installing dahdi-dkms is all that is needed to compile the kernel module for the current kernel provided that we have the linux-headers-* package matching the installed kernel. For instance, if you use linux-image-amd64, you would also install linux-headers-amd64.
sudo apt install zfs-dkms
dkms status
# zfs/2.1.5, 5.19.17, x86_64: installed
dkms build
dkms install
dkms uninstall zfs/2.1.5
dkms add
dkms remove zenpower/$(VERSION) --all
例子:Ta180m/zenpower3: Migrated to Gitea (github.com)
- 安装 header
- pve 使用自己的内核,因此也是安装自己的 header
dkms-install:
dkms --version >> /dev/null
mkdir -p $(DKMS_ROOT_PATH)
cp $(CURDIR)/dkms.conf $(DKMS_ROOT_PATH)
cp $(CURDIR)/Makefile $(DKMS_ROOT_PATH)
cp $(CURDIR)/zenpower.c $(DKMS_ROOT_PATH)
sed -e "s/@CFLGS@/${MCFLAGS}/" \
-e "s/@VERSION@/$(VERSION)/" \
-i $(DKMS_ROOT_PATH)/dkms.conf
dkms add zenpower/$(VERSION)
dkms build zenpower/$(VERSION)
dkms install zenpower/$(VERSION)
dkms-uninstall:
dkms remove zenpower/$(VERSION) --all
rm -rf $(DKMS_ROOT_PATH)
删除内核¶
或者手动删除
内核模块¶
find /lib/modules/$(uname -r) -type f -name '*.ko'
modprobe xxx
modprobe -r xxx # 删除
lsmod |grep xxx
rmmod xxx
-
depmod: 用于更新内核模块依赖信息。depmod命令会扫描系统中的内核模块,并为它们生成一个依赖关系文件,通常在/lib/modules/目录下。这个文件通常被命名为modules.dep,它列出了每个模块及其依赖的其他模块,以确保内核模块正确加载和卸载。 -
lsmod: 用于列出当前加载到内核中的模块。lsmod命令会显示已加载模块的列表,以及它们的大小、使用次数和依赖关系。 -
modprobe: 用于动态加载和卸载内核模块。modprobe命令可以根据模块名称自动加载模块,并处理其依赖关系。它还可以用于卸载模块,或者通过参数指定模块选项。 -
insmod: 用于手动加载一个内核模块。insmod命令可以直接加载指定的模块文件,但不会处理模块的依赖关系。因此,通常建议使用modprobe来加载模块,以确保正确处理依赖关系。 -
rmmod: 用于从内核中卸载一个已加载的模块。rmmod命令接受模块名称作为参数,并会尝试卸载该模块,前提是它没有被其他模块所使用。 -
modinfo: 用于获取有关内核模块的信息。modinfo命令可以列出有关模块的信息,如作者、描述、参数等。 -
ls /lib/modules/: 这个命令用于查看系统中可用的内核模块。在/lib/modules/目录下,你可以找到与已安装内核版本相关的模块文件和依赖信息。