- C++ 语言新机制(如闭包,for_each)
- C++ STL 使用
- 容器
- 算法库
- 常见算法记录
现代 c++ 教程¶
[现代 C++ 教程:高速上手 C++ 11/14/17/20 - Modern C++ Tutorial: C++ 11/14/17/20 On the Fly (changkun.de)
在传统 C++ 中,不同的对象有着不同的初始化方法,例如普通数组、POD(Plain Old Data,即没有构造、析构和虚函数的类或结构体)类型都可以使用
{}进行初始化,也就是我们所说的初始化列表。而对于类对象的初始化,要么需要通过拷贝构造、要么就需要使用()进行。其次,C++11 还提供了统一的语法来初始化任意的对象,例如:
decltype
区间 for 迭代
for (auto &element : vec) {
element += 1; // writeable
}
for (auto element : vec)
std::cout << element << std::endl; // read only
using 函数指针格式更简单
C++ 语言新特性¶
默认为 c++11,其它标准特性会显示说明。
tamplate¶
用于表示一般类型的函数,类。编译时根据需要生成对应类型的实例。
- 函数模板
- 类模板
template <class identifier> function_declaration;
template <typename identifier> function_declaration;
class和typename效果是完全一样的。
类型转换 cast¶
- C 语言风格的类型转换被弃用(即在变量前使用
(convert_type)),应该使用static_cast、reinterpret_cast、const_cast来进行类型转换。`**
lambda 表达式¶
- lambda = 匿名函数
- 闭包 = 捕获了 local scope 外变量的 lambda 函数
Lambda expressions (since C++11) - cppreference.com
隐式捕获
[]空捕获列表[name1, name2, ...]捕获一系列变量[&]引用捕获,让编译器自行推导引用列表[=]值捕获,让编译器自行推导值捕获列表 表达式捕获
上面提到的值捕获、引用捕获都是已经在外层作用域声明的变量,因此这些捕获方式捕获的均为左值,而不能捕获右值。
#include <iostream>
#include <memory> // std::make_unique
#include <utility> // std::move
void lambda_expression_capture() {
auto important = std::make_unique<int>(1);
auto add = [v1 = 1, v2 = std::move(important)](int x, int y) -> int {
return x+y+v1+(*v2);
};
std::cout << add(3,4) << std::endl;
}
泛型 lambda
递归¶
- 必须[&],因为函数定义在函数体外,需要使用闭包抓取。
- 不能使用 auto,需要使用 function 定义。因为 auto 需要根据函数内容推断,而闭包又需要引用外部函数定义。
#include <functional>
// Function < return type (parameter types) > functionName
function<int(int)> f = [&](int i) {
if (i == 0)
return 1;
return f(i - 1) * i;
}
右值引用¶
传统 C++ 通过拷贝构造函数和赋值操作符为类对象设计了拷贝/复制的概念,但为了实现对资源的移动操作,调用者必须使用先复制、再析构的方式,否则就需要自己实现移动对象的接口。试想,搬家的时候是把家里的东西直接搬到新家去,而不是将所有东西复制一份(重买)再放到新家、再把原来的东西全部扔掉(销毁),这是非常反人类的一件事情。
传统的 C++ 没有区分『移动』和『拷贝』的概念,造成了大量的数据拷贝,浪费时间和空间。右值引用的出现恰好就解决了这两个概念的混淆问题,例如:
#include <iostream>
class A {
public:
int *pointer;
A():pointer(new int(1)) {
std::cout << "构造" << pointer << std::endl;
}
A(A& a):pointer(new int(*a.pointer)) {
std::cout << "拷贝" << pointer << std::endl;
} // 无意义的对象拷贝
A(A&& a):pointer(a.pointer) {
a.pointer = nullptr;
std::cout << "移动" << pointer << std::endl;
}
~A(){
std::cout << "析构" << pointer << std::endl;
delete pointer;
}
};
// 防止编译器优化
A return_rvalue(bool test) {
A a,b;
if(test) return a; // 等价于 static_cast<A&&>(a);
else return b; // 等价于 static_cast<A&&>(b);
}
int main() {
A obj = return_rvalue(false);
std::cout << "obj:" << std::endl;
std::cout << obj.pointer << std::endl;
std::cout << *obj.pointer << std::endl;
return 0;
}
- 首先会在
return_rvalue内部构造两个A对象,于是获得两个构造函数的输出; - 函数返回后,产生一个将亡值,被
A的移动构造(A(A&&))引用,从而延长生命周期,并将这个右值中的指针拿到,保存到了obj中,而将亡值的指针被设置为nullptr,防止了这块内存区域被销毁。
#include <iostream> // std::cout
#include <utility> // std::move
#include <vector> // std::vector
#include <string> // std::string
int main() {
std::string str = "Hello world.";
std::vector<std::string> v;
// 将使用 push_back(const T&), 即产生拷贝行为
v.push_back(str);
// 将输出 "str: Hello world."
std::cout << "str: " << str << std::endl;
// 将使用 push_back(const T&&), 不会出现拷贝行为
// 而整个字符串会被移动到 vector 中,所以有时候 std::move 会用来减少拷贝出现的开销
// 这步操作后,str 中的值会变为空
v.push_back(std::move(str));
// 将输出 "str: "
std::cout << "str: " << str << std::endl;
return 0;
}
小技巧¶
pair 解包¶
需要 c++17
多元 swap¶
- 将 4 个元素循环左移
tie(matrix[i][j], matrix[n - j - 1][i], matrix[n - i - 1][n - j - 1], matrix[j][n - i - 1]) \
= make_tuple(matrix[n - j - 1][i], matrix[n - i - 1][n - j - 1], matrix[j][n - i - 1], matrix[i][j]);
string_view¶
- c++17
避免了 string 的复制
问题¶
emplace_back, push_back¶
c++ - emplace_back() vs push_back when inserting a pair into std::vector - Stack Overflow
emplace 被设计用来避免构建临时变量,然后拷贝复制。接收的是构造函数参数
因此改成这样是正确的
ans.emplace_back(prime, cnt);
ans.emplace_back(make_pair(prime, cnt)) //这样写虽然结果正确,但是 emplace 就没有意义了,因为已经显示构建了临时变量
另外{1, 2}不是一个表达式,具体含义和场景有关。
emplace 一个复杂对象¶
c++ - how to use std::vector::emplace_back for vector<vector? - Stack Overflow
解法一:
解法二:使用 move
for (int i = 0; i < 10000; ++i) {
std::vector<int> v(10000, 0); // will become empty afterward
res.emplace_back(std::move(v)); // can be replaced by
// res.push_back(std::move(v));
}
初始化 pair array¶
initialization - C++: array<> too many initializers - Stack Overflow
array<pair<int, int>, 8> direction = {{{-1, -1}, {-1, 0}, {-1, 1}, {0, -1}, {0, 1}, {1, -1}, {1, 0}, {1, 1}}}; #需要多一层{}
C 有点烦人的地方¶
隐式类型转换¶
隐式转换规则
- 注意:int -> unsigned
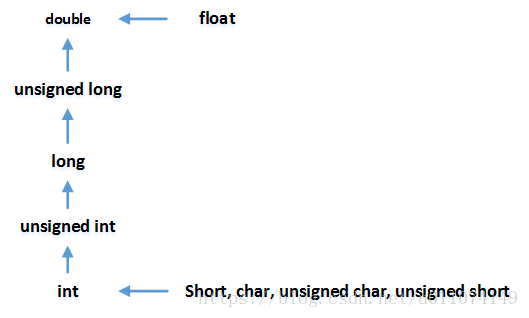
m*n直接乘会溢出
直接min又会出现两边参数类型不一样的问题
其它¶
struct 初始化¶
c 中需要typedef struct aaa{} bbb;
struct aaa var或者bbb var;
C++ 中
- 可以定义构造函数
- 可以直接初始化变量
- struct aaa 后可以直接 aaa 定义变量
定义构造函数,new 时通过圆括号实例化
struct ListNode
{
double value;
ListNode *next;
//构造函数
ListNode(double valuel, ListNode *nextl = nullptr)
{
value = value1;
next = next1;
}
};
ListNode *secondPtr = new ListNode(13.5);
ListNode *head = new ListNode(12.5, secondPtr);
也可以使用花括号实例化
C++ 标准库¶
stream¶
#include <sstream>
int val=123;
// object from the class stringstream
stringstream geek;
// inserting integer val in geek stream
geek << val;
// The object has the value 123
// and stream it to the string x
string x;
geek >> x;
异常处理¶
C++ 异常处理 - C++ 教程 (yiibai.com) (41 封私信 / 80 条消息) 如何用 C 语言实现异常/状况处理机制? - 知乎 (zhihu.com) Programming in Lua(二)- 异常与错误码 | 技术奇异点 (techsingular.net) C 语言中的异常处理 - Sirk - 博客园 (cnblogs.com)
自从 C 被发明初来,C 程序员就习惯使用错误代码,但如果一个函数通过设置一个状态变量或返回错误代码来表示一个异常状态,没有办法保证函数调用者将一定检测变量或测试错误代码。结果程序会从它遇到的异常状态继续运行,异常没有被捕获,程序立即会终止执行。由
抛出异常¶
throw 语句决定抛出异常类型
double division(int a, int b)
{
if( b == 0 )
{
throw "Division by zero condition!";
}
return (a/b);
}
捕获异常¶
- 按情况捕获不同类型异常
try
{
// protected code
}catch( ExceptionName1 e1 )
{
// catch block
}catch( ExceptionName2 e2 )
{
// catch block
}
...捕获任意类型
异常类型¶
异常可以是任意类型,由 throw 语句决定
c++<exception>定义了标准异常类型
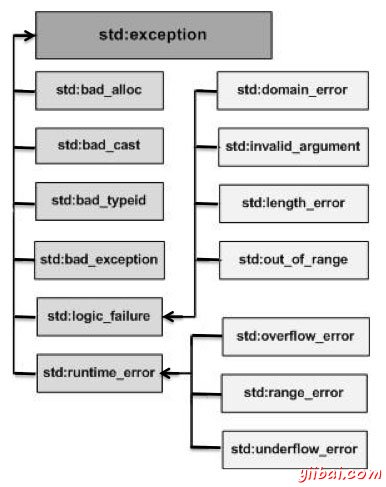
what() 方法返回异常原因
常数¶
https://cplusplus.com/reference/climits/
#include <cstdio>
#include <climits>
using namespace std;
int main(){
printf("SCHAR_MIN: %d\n", SCHAR_MIN); // -128
printf("SCHAR_MAX: %d\n", SCHAR_MAX); // 127
printf("UCHAR_MAX: %d\n", UCHAR_MAX); // 255
printf("CHAR_MIN: %d\n", CHAR_MIN); // -128
printf("CHAR_MAX: %d\n", CHAR_MAX); // 127
printf("INT_MIN: %d\n", INT_MIN); // -2147483648
printf("INT_MAX: %d\n", INT_MAX); // 2147483647
printf("UINT_MAX: %u\n", UINT_MAX); // 4294967295
printf("LONG_MIN: %ld\n", LONG_MIN); // -9223372036854775808
printf("LONG_MAX: %ld\n", LONG_MAX); // 9223372036854775807
printf("ULONG_MAX: %lu\n", ULONG_MAX); // 18446744073709551615
printf("LLONG_MIN: %lld\n", LLONG_MIN); // -9223372036854775808
printf("LLONG_MAX: %lld\n", LLONG_MAX); // 9223372036854775807
printf("ULLONG_MAX: %llu\n", ULLONG_MAX); // 18446744073709551615
printf("DECIMAL_DIG: %d\n", DECIMAL_DIG); //21
printf("FLT_MIN: %e\n", FLT_MIN); // 1.175494e-38
printf("FLT_MAX: %e\n", FLT_MAX); // 3.402823e+38
printf("DBL_MIN: %e\n", DBL_MIN); // 2.225074e-308
printf("DBL_MAX: %e\n", DBL_MAX); // 1.797693e+308
printf("LDBL_MIN: %Le\n", LDBL_MIN); // 3.362103e-4932 //使用 Lf format
printf("LDBL_MAX: %Le\n", LDBL_MAX); // 1.189731e+4932
printf("sizeof(double)) : %ld\n", sizeof(double)); // 8
printf("sizeof(long double)): %ld\n", sizeof(long double)); // 16 (有些可能为 10)
printf("FLT_EPSILON: %e\n", FLT_EPSILON); // 1.192093e-07
printf("DBL_EPSILON: %e\n", DBL_EPSILON); // 2.220446e-16
return 0;
}
容器¶
array¶
转换成 C 的数组
void foo(int *p, int len) {
return;
}
std::array<int, 4> arr = {1,2,3,4};
// C 风格接口传参
// foo(arr, arr.size()); // 非法,无法隐式转换
foo(&arr[0], arr.size());
foo(arr.data(), arr.size());
vector¶
构造函数
// default (1)
explicit vector (const allocator_type& alloc = allocator_type());
// fill (2)
explicit vector (size_type n);
vector (size_type n, const value_type& val, const allocator_type& alloc = allocator_type());
// range (3)
template <class InputIterator> vector (InputIterator first, InputIterator last, const allocator_type& alloc = allocator_type());
// copy (4)
vector (const vector& x);vector (const vector& x, const allocator_type& alloc);
// move (5)
vector (vector&& x);vector (vector&& x, const allocator_type& alloc);
// initializer list (6)
vector (initializer_list<value_type> il, const allocator_type& alloc = allocator_type());
initializer_list
# 初始化
vector<int, vector<int>> v(m, vector<int>(n, 0)); //mxn 矩阵
vector<int> v = {1, 2, 3, 4};
vector<int> v2(initializer_list<int>{1,2})
vector<int> v2{1,2}
erase & insert¶
erase
- 返回删除元素的下一个元素的迭代器
iterator erase (const_iterator position);
iterator erase (const_iterator first, const_iterator last);
insert
- 在 postion 前面插入
- 返回第一个新插入元素的迭代器
string¶
构造函数,常用
- fill:n, char
- c-str:以 0 结尾的字符串
- buffer:buf + len
- substring
// default (1)
string();
// copy (2)
string (const string& str);
// substring (3)
string (const string& str, size_t pos, size_t len = npos);
// from c-string (4)
string (const char* s);
// from buffer (5)
string (const char* s, size_t n);
// fill (6)
string (size_t n, char c);
// range (7)
template <class InputIterator> string (InputIterator first, InputIterator last);
// initializer list (8)
string (initializer_list<char> il);
// move (9)
string (string&& str) noexcept;
获得 c str
插入删除¶
插入
string 特有方式:下标
- 第一个参数为 pos,在 pos 左侧插入
- 0<= pos <= n,n+1 个插入位置
- 第二个参数类似于构造函数各种字符串类型
标准迭代器方式
- 删除单个迭代器对应元素,或者使用输入迭代器指定一个 range
- 返回更新后的迭代器
iterator insert (const_iterator p, char c);
template <class InputIterator>iterator insert (iterator p, InputIterator first, InputIterator last);
删除
- string 特有方式:删除子串
- 标准迭代器方式
查找¶
返回第一个匹配的索引
string (1)
size_t find (const string& str, size_t pos = 0) const noexcept;
c-string (2)
size_t find (const char* s, size_t pos = 0) const;
buffer (3)
size_t find (const char* s, size_t pos, size_type n) const;
character (4)
size_t find (char c, size_t pos = 0) const noexcept;
没找到返回 npos
This value, when used as the value for a len (or sublen) parameter in string's member functions, means "until the end of the string". As a return value, it is usually used to indicate no matches.
拼接¶
- 拼接是在原本字符串上修改,如果不需要改变源字符串使用
+ - append 单个字符:
digits.append(1, 'x');
// string (1)
string& append (const string& str);
// substring (2)
string& append (const string& str, size_t subpos, size_t sublen);
// c-string (3)
string& append (const char* s);
// buffer (4)
string& append (const char* s, size_t n);
// fill (5)
string& append (size_t n, char c);
// range (6)
template <class InputIterator> string& append (InputIterator first, InputIterator last);
// initializer list(7)
string& append (initializer_list<char> il);
//range
template <class InputIterator> string (InputIterator first, InputIterator last);
//initializer list
string (initializer_list<char> il);
size() <=> length()
转换为 C string,注意返回值是 const
替换¶
- string:
string& replace (size_t pos, size_t len, const string& str); - substring
- c-string
- buffer(char* s , size_t n)
- fill:
string& replace (size_t pos, size_t len, size_t n, char c);
// replacing in a string
#include <iostream>
#include <string>
int main ()
{
std::string base="this is a test string.";
std::string str2="n example";
std::string str3="sample phrase";
std::string str4="useful.";
// replace signatures used in the same order as described above:
// Using positions: 0123456789*123456789*12345
std::string str=base; // "this is a test string."
str.replace(9,5,str2); // "this is an example string." (1)
str.replace(19,6,str3,7,6); // "this is an example phrase." (2)
str.replace(8,10,"just a"); // "this is just a phrase." (3)
str.replace(8,6,"a shorty",7); // "this is a short phrase." (4)
str.replace(22,1,3,'!'); // "this is a short phrase!!!" (5)
// Using iterators: 0123456789*123456789*
str.replace(str.begin(),str.end()-3,str3); // "sample phrase!!!" (1)
str.replace(str.begin(),str.begin()+6,"replace"); // "replace phrase!!!" (3)
str.replace(str.begin()+8,str.begin()+14,"is coolness",7); // "replace is cool!!!" (4)
str.replace(str.begin()+12,str.end()-4,4,'o'); // "replace is cooool!!!" (5)
str.replace(str.begin()+11,str.end(),str4.begin(),str4.end());// "replace is useful." (6)
std::cout << str << '\n';
return 0;
}
子串¶
- 注意第二个参数是字符串长度
字符串和数字转换¶
C++ 字符串和数字转换完全攻略 (biancheng.net)
- 使用字符串流对象
- 使用 stoX, to_string
stoX
- pos 返回第一个转换失败的位置,如
stoi("-34iseven", &pos),pos 为 3 - 抛出异常 invalid_argument
string to_string(int value)
string to_string(long value)
string to_string(double value)
int stoi(const strings str, size_t* pos = 0, int base = 10)
long stol(const strings str, size_t* pos = 0, int base = 10)
float stof(const strings str, size_t* pos = 0)
double stod(const strings str, size_t* pos = 0)
string_view(c++17)¶
会发现 c++ string 是 basic_string 模板类的实例。string_view 则是 basic_string_view 的实例。
typedef std::__cxx11::basic_string<char> std::string
using std::string_view = std::basic_string_view<char>
string_view 描述了一个常量的、连续的 charT 序列 (constant contiguous sequence of CharT),下标从 0 开始。
- 可以看作一个包含 const 指针和 size 的结构体。
- 通过
data()获得 const_pointer(const char *)
构造函数¶
constexpr basic_string_view( const basic_string_view& other ) noexcept
= default;
constexpr basic_string_view( const CharT* s ); # 不包含结尾null字符
constexpr basic_string_view( const CharT* s, size_type count ); #前count个字符,可能包含null
const char* one_0_two = "One\0Two";
std::string_view one_two_v{one_0_two, 7}; //size = 7
std::string_view one_v{one_0_two}; //size = 3
//虽然没有 string 的构造函数,但是 string 会自动转换为 string_view
std::string cppstr = "Foo";
std::string_view cppstr_v(cppstr); // overload (2), after
// std::string::operator string_view
operator"" sv
Constructs a string_view from a string literal. Requires namespace std::literals::string_view_literals.
其它函数¶
比较函数
template< class CharT, class Traits >
constexpr bool operator==( std::basic_string_view<CharT,Traits> lhs,
std::basic_string_view<CharT,Traits> rhs ) noexcept;
还可以获得子 string_view
find 返回 offset
注意事项¶
c++ - How to efficiently get a string_view for a substring of std::string - Stack Overflow
函数不应该返回 string_view。The consensus of advice from this group is that std::string_view must never be returned from a function, which means that my first offering above is bad form.
As a result, std::string_view should be used with the utmost care, because from a memory management point of view it is equivalent to a copyable pointer pointing into the state of another object, which may no longer exist. However, it looks and behaves in all other respects like a value type.
string 比较避免复制¶
C 字符串比较¶
int strcmp (const char* str1, const char* str2);
int strncmp(const char *str1, const char *str2, size_t n)
strncmp: This function starts comparing the first character of each string. If they are equal to each other, it continues with the following pairs until the characters differ, until a terminating null-character is reached, or until num characters match in both strings, whichever happens first.
- 注意是
const char*,否则传入string.c_str()时会报错
int my_strcmp(const char *p1, const char *p2) {
while (*p1 && *p2) {
if (*p1 != *p2) {
return *p1 - *p2;
}
p1++;
p2++;
}
return *p1 - *p2;
}
int my_strncmp(const char *p1, const char *p2, int n) {
while (*p1 && *p2 && n) {
if (*p1 != *p2) {
return *p1 - *p2;
}
p1++;
p2++;
n--;
}
return *p1 - *p2;
}
my_strcmp(s1.c_str(), s1.c_str());
string_view == string¶
c++ - c++17 Ambiguity when compare string_view with string - Stack Overflow 问题:string_view 和 string 都能转换成对方,以下代码是否有歧义
std::string s1 = "123";
std::string_view s2 = "123";
// in the following comparison, will s1 use the convert operator to generate a string_view, or will s2 use string's string_view constructor to generate a string?
if (s1 == s2) {...}
- string 可以隐式转换为 string_view
==操作符有一个 override 版本,支持参数隐式转换为 string_view- 因此
s1==s2时使用 string_view
map & set¶
lower_boud¶
可以用于查找 map 中最接近 x 的元素
auto it = s.lower_bound(num);
int right = *it;
int left = *(--it); // it-1 是不行的,it 是双向迭代器,不支持 it+i/it-i 操作
- 注意是
s.lower_bound不是lower_bound(s.begin(), s.end())- 一次 oj 中发现后者可以运行,但是会超时
插入元素¶
pair<iterator,bool> insert (const value_type& val);
template <class P> pair<iterator,bool> insert (P&& val);
- 返回值:ret.first 为插入元素的迭代器。ret.second 指示元素是否存在
//插入
mymap.insert ( std::pair<char,int>('a',100) );
mymap.insert ( std::pair<char,int>('z',200) );
//返回值
std::pair<std::map<char,int>::iterator,bool> ret;
ret = mymap.insert ( std::pair<char,int>('z',500) );
if (ret.second==false) {
std::cout << "element 'z' already existed";
std::cout << " with a value of " << ret.first->second << '\n';
}
//使用 [] 插入,当 key 不存在时会自动创建元素
mapped_type& operator[] (const key_type& k)
//等价于如下调用
(
*( //*iterator
(//pair<iterator,bool>
this->insert(make_pair(k, mapped_type()))
).first
)
);
std::map<char,std::string> mymap;
mymap['a']="an element";
mymap['b']="another element";
mymap['c']=mymap['b'];
cout << "mymap['d'] is " << mymap['d'] // 空,对于 int mapped_type,默认初始化为 0
//使用 at() 来修改元素,当不存在时会报错
mapped_type& at (const key_type& k)
查找¶
if (myset.count(x)) {
// x is in the set, count is 1
} else {
// count zero, i.e. x not in the set
}
c++ 20
求交¶
复杂到还不如不用
c++ - How to find the intersection of two STL sets? - Stack Overflow
I would like to understand why such a fundamental operation on sets requires such an arcanely verbose incantation.
自定义 Key 类型¶
map¶
- 有序 map,需要自定义<运算
- 注意函数需要声明为 const
typedef struct Key{
char cnt[26];
Key(){
for(int i=0; i<26; i++){
cnt[i] = 0;
}
}
bool operator<(const Key &k2) const{
for(int i=0; i<26; i++){
if(cnt[i]<k2.cnt[i]){
return true;
}else if(cnt[i]>k2.cnt[i]){
return false;
}
}
return false;
}
}Key;
unordered_map¶
hash - C++ unordered_map using a custom class type as the key - Stack Overflow
- 需要自定义:1)hash 函数,2)重载
==运算 - 定义时需要在模板参数中定义 hash 函数的类型,并且传递实参(函数对象,lambda,函数名)
// 自定义对 array<int, 26> 类型的哈希函数
auto arrayHash = [fn = hash<int>{}] (const array<int, 26>& arr) -> size_t {
return accumulate(arr.begin(), arr.end(), 0u, [&](size_t acc, int num) {
return (acc << 1) ^ fn(num);
});
};
unordered_map<array<int, 26>, vector<string>, decltype(arrayHash)> mp(0, arrayHash);
queue¶
- 和 stack 一样,也只有 push, pop
- 但是可以访问两头。front, back。
- push 对应 back,pop 对应 front。考虑一个水平放置的羽毛球筒,从右往左放入羽毛球。push(back), pop(front)
queues are implemented as containers adaptors, which are classes that use an encapsulated object of a specific container class as its underlying container
底层容器至少需要实现以下方法
- empty
- size
- front
- back
- push_back
- pop_front The standard container classes deque and list fulfill these requirements
list, deque¶
std::list is a container that supports constant time insertion and removal of elements from anywhere in the container. Fast random access is not supported. It is usually implemented as a doubly-linked list.
deque
- 和 vector 类似,支持随机读写,并且支持在两头插入删除。
- 底层一般也是基于 array
While vectors use a single array that needs to be occasionally reallocated for growth, the elements of a deque can be scattered in different chunks of storage, with the container keeping the necessary information internally to provide direct access to any of its elements in constant time and with a uniform sequential interface (through iterators).
deque 可以便遍历,但是 queue 无法遍历
元组¶
std::make_tuple: 构造元组std::get: 获得元组某个位置的值std::tie: 元组拆包
auto student = std::make_tuple(3.8, 'A', "张三");
cout << "姓名:" << std::get<2>(student);
double gpa;
char grade;
std::string name;
// 元组进行拆包
std::tie(gpa, grade, name) = get_student(1);
优先队列¶
示例
int findKthLargest(vector<int>& nums, int k) {
priority_queue<int, vector<int>, less<int>> max_heap(nums.begin(), nums.end());
int ans;
for(int i=0; i<k; i++){
ans = max_heap.top();max_heap.pop();
}
return ans;
}
模板类定义
template<
class T,
class Container = std::vector<T>,
class Compare = std::less<typename Container::value_type>
> class priority_queue;
构造函数
- 建堆复杂度为 O(3n)
- algorithm - How is make_heap in C++ implemented to have complexity of 3N? - Stack Overflow
- The constructor effectively initializes the comparison and container objects and then calls algorithm make_heap on the range that includes all its elements before returning.
- 不理解为什么构造函数中还要指定 comp 和 ctnr,后面示例中也没有传递该参数啊?
- The template parameter is the type of the comparator. You still need to pass an instance of the comparator to the priority_queue constructor, and that is when you can construct the comparator instance with whatever parameters you like.Priority Queue of custom Class using Comparator with argument on constructor in C++ - Stack Overflow
priority_queue (const Compare& comp, const Container& ctnr);
template <class InputIterator> priority_queue (InputIterator first, InputIterator last, const Compare& comp, const Container& ctnr);
示例
int myints[]= {10,60,50,20};
std::priority_queue<int> first;
std::priority_queue<int> second (myints,myints+4);
std::priority_queue<int, std::vector<int>, std::greater<int> > #使用最小堆,指定greater
third (myints,myints+4);
自定义比较函数
auto cmp = [&](const pair<int, int>& x, const pair<int, int>& y) {
return arr[x.first] * arr[y.second] > arr[x.second] * arr[y.first];
};
priority_queue<pair<int, int>, vector<pair<int, int>>, decltype(cmp)> q(cmp);
- 实现为容器适配器,底层实例化一个特定的容器类对象。底层容器可以使用 vector 和 deque,默认为 vector
- top + pop
- 总结:两头的使用 front + push(queue,deque)。一头的使用 top + pop(stack, prority)
底层自动使用 make_heap
The standard container adaptor priority_queue calls make_heap, push_heap and pop_heap automatically to maintain heap properties for a container.
直接使用 make_heap 接口例子
int myints[] = {10,20,30,5,15};
std::vector<int> v(myints,myints+5);
std::make_heap (v.begin(),v.end());
std::cout << "initial max heap : " << v.front() << '\n';
std::pop_heap (v.begin(),v.end()); v.pop_back();
std::cout << "max heap after pop : " << v.front() << '\n';
v.push_back(99); std::push_heap (v.begin(),v.end());
std::cout << "max heap after push: " << v.front() << '\n';
std::sort_heap (v.begin(),v.end());
缺陷¶
无法判断一个元素是否位于优先队列中
无法遍历:c++ - How to iterate over a priority_queue? - Stack Overflow
- 真够 sb 的
算法¶
最大最小¶
find_if¶
std::find, std::find_if, std::find_if_not - cppreference.com
template< class InputIt, class T >
InputIt find( InputIt first, InputIt last, const T& value );
template< class InputIt, class UnaryPredicate >
InputIt find_if( InputIt first, InputIt last, UnaryPredicate p );
template< class InputIt, class UnaryPredicate >
InputIt find_if_not( InputIt first, InputIt last, UnaryPredicate q );
实现
template<class InputIt, class UnaryPredicate>
constexpr InputIt find_if(InputIt first, InputIt last, UnaryPredicate p)
{
for (; first != last; ++first)
if (p(*first))
return first;
return last;
}
例子
int n1 = 3;
int n2 = 5;
auto is_even = [](int i) { return i % 2 == 0; };
auto result1 = std::find(begin(v), end(v), n1);
auto result2 = std::find(begin(v), end(v), n2);
auto result3 = std::find_if(begin(v), end(v), is_even);
//check if result == end(v)
any_of, none_of¶
std::all_of, std::any_of, std::none_of - cppreference.com
template< class InputIt, class UnaryPredicate >
bool all_of( InputIt first, InputIt last, UnaryPredicate p );
template< class ExecutionPolicy, class ForwardIt, class UnaryPredicate >
bool all_of( ExecutionPolicy&& policy, ForwardIt first, ForwardIt last,
UnaryPredicate p );
- all_of: Checks if unary predicate p returns true for all elements in the range
[first,last). - any_of: Checks if unary predicate p returns true for at least one element in the range
[first,last). - none_of: Checks if unary predicate p returns true for no elements in the range
[first,last).
iota¶
itoa 是第九个希腊字母的音标,表示小写字母\(\iota\)(可以看 latex 是如何写的)
源自 APL 编程语言,符号 itoa 表示整数向量 c++ - What does iota of std::iota stand for? - Stack Overflow
The interval vector ⍳j(n) is defined as the vector of integers beginning with j.
template<class ForwardIt, class T>
constexpr // since C++20
void iota(ForwardIt first, ForwardIt last, T value)
{
while (first != last)
{
*first++ = value;
++value;
}
}
fill¶
迭代器¶
- 前向迭代器(forward iterator)
++p,p++,*p
- 双向迭代器(bidirectional iterator)
--p, p--
- 随机访问迭代器(random access iterator)
p+i, p-i, p[i]
迭代适配器¶
反向迭代器 插入迭代器
advance(it, n):it 表示某个迭代器,n 为整数。该函数的功能是将 it 迭代器前进或后退 n 个位置。 prev(it):it 为指定的迭代器,该函数默认可以返回一个指向上一个位置处的迭代器。注意,it 至少为双向迭代器。 next(it):t 为指定的迭代器,该函数默认可以返回一个指向下一个位置处的迭代器。注意,it 最少为前向迭代器。 注意 advance 修改原迭代器,prev,next 返回新迭代器。
迭代器失效处理¶
STL 容器迭代器失效情况分析、总结 | Ivanzz (ivanzz1001.github.io)
vector 底层是连续数组,删除某个元素时,需要对元素进行移动,此时删除元素后面的迭代器均会失效。
- 当使用一个容器的 insert 或者 erase 函数通过迭代器
插入或删除元素可能会导致迭代器失效,因此我们为了避免危险,应该获取 insert 或者 erase 返回的迭代器,以便用重新获取的新的有效的迭代器进行正确的操作 - 以下代码实现对排序的数组去重。
int removeDuplicates(vector<int>& nums) {
for (auto it = nums.begin()+1; it != nums.end();) {
if (*it == *(it - 1)) {
it = nums.erase(it);
}else{
it++;
}
}
return nums.size();
}
- list:erase 时只有删除的元素迭代器失效,其余仍然有效。
- deque:首尾插入删除没关系。但是中间插入删除使得所有迭代器失效
- set, map:不影响其它元素
杂¶
计时¶
Date and time utilities - cppreference.com
问题¶
迭代器边遍历边删除¶
c++ - Deleting elements from std::set while iterating - Stack Overflow
可以使用一个 current 存储当前值
for (auto it = unvisit.begin(); it != unvisit.end();) {
auto cur = it++;
int y = *cur;
if (gcd(x, y) > 1) {
s.push(y);
unvisit.erase(cur);
}
}
常见取整¶
- std::floor(x) == (int) ?
- std::ceil(x) 如何实现
- 其实 float 转 int 是如何实现的呢?有专门指令吗?
c++ - Ceil function: how can we implement it ourselves? - Stack Overflow
- 根据 IEEE754 标准实现
- if(x == (int) x)
实际
- SSE, AVX 专门的一类 CVT 指令 https://db.in.tum.de/~finis/x86-intrin-cheatsheet-v2.1.pdf
hash map 使用 pair 作为 key¶
c++ - Why can't I compile an unordered_map with a pair as key? - Stack Overflow
对于非基本类型 key 的 hash map,c++ 要求自定义 hash 函数
两种方法:
- wrap 一个针对一般 pair 类型的 hash 函数
- 这样不能完全保证 hash 函数是比较好的
// Only for pairs of std::hash-able types for simplicity.
// You can of course template this struct to allow other hash functions
struct pair_hash {
template <class T1, class T2>
std::size_t operator () (const std::pair<T1,T2> &p) const {
auto h1 = std::hash<T1>{}(p.first);
auto h2 = std::hash<T2>{}(p.second);
// Mainly for demonstration purposes, i.e. works but is overly simple
// In the real world, use sth. like boost.hash_combine
return h1 ^ h2;
}
};
unordered_map<pair<int, int>, int, pair_hash> memo; //(S, i) -> #permutation
- 自己 wrap 一个生成 key 的函数。
- 这样使用的是系统的 hash 函数,效果有保障
- 需要保证生成的 key 是唯一的。
inline size_t get_key(int i, int j) {
return (size_t)i << 32 | (unsigned int)j;
}
unordered_map<size_t, int> memo;
auto key = get_key(S, prev);
if(memo.count(key)){
return memo[key];
}
常见算法¶
二分查找¶
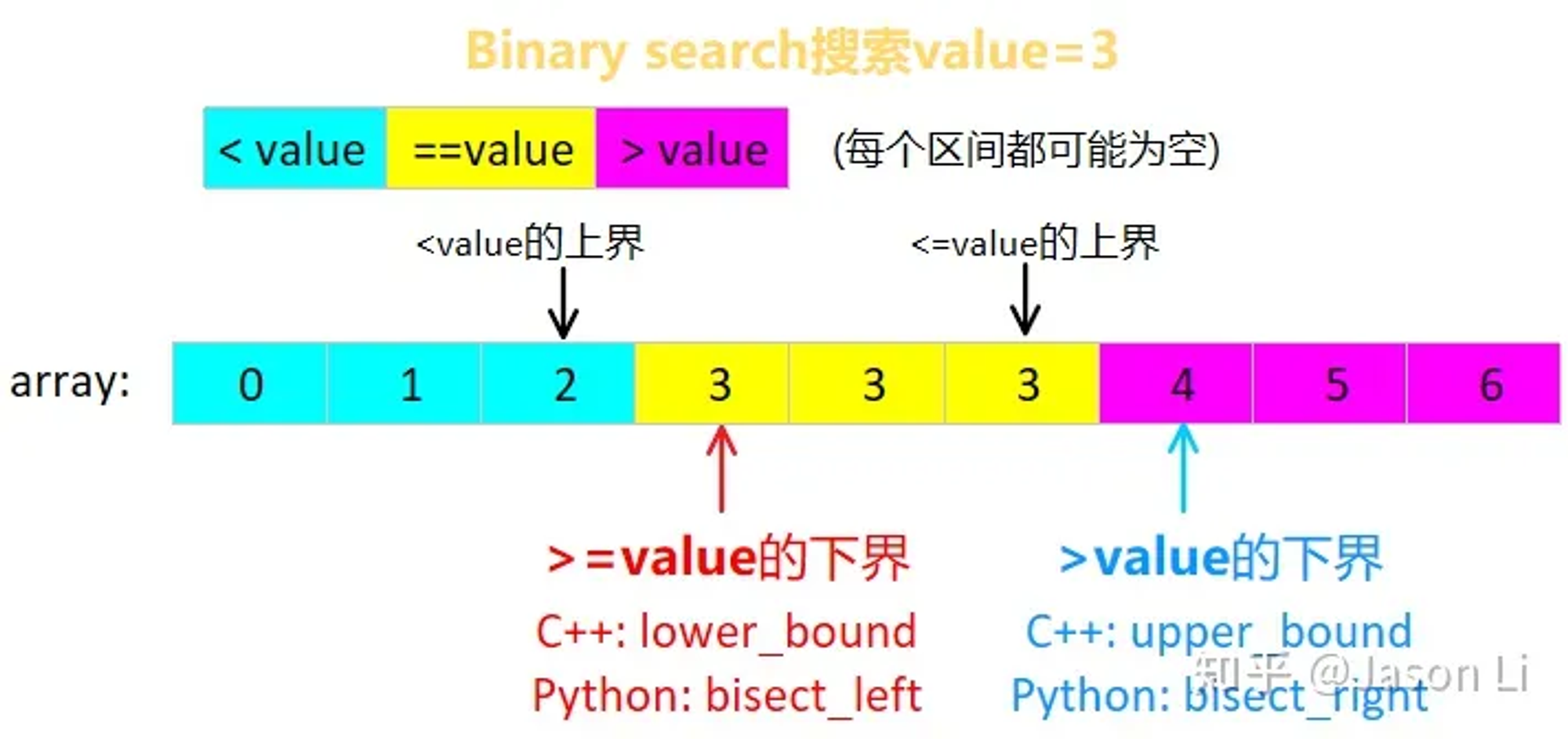
- 如上图,将数组染上颜色
- 如果 mid 是蓝色 (<成立)
- 对于闭区间和左闭右开,L = mid+1
- 对于开区间,L = mid
- 如果 mid 是其它
- 对于闭区间,R = mid - 1
- 对于开区间和左闭右开,R = mid
循环不变量 闭区间
- L - 1 = 蓝色
- R + 1 = 红色
- 结束时 L = R + 1 左闭右开
- L - 1 = 蓝色
- R = 红色
- 结束时 L = R 开区间
- L = 蓝色
- R = 红色
- 结束时 L = R - 1
巧妙转换成二分查找问题:786. 第 K 个最小的素数分数

简单类型 comp 定义¶
三种?
- 函数对象
- lambda 表达式
- 函数指针
这里的greater()是函数对象:Generically, function objects are instances of a class with member function operator() defined.
实现
template <class T> struct greater {
bool operator() (const T& x, const T& y) const {return x>y;}
typedef T first_argument_type;
typedef T second_argument_type;
typedef bool result_type;
};
复杂类型 comp 定义¶
vector<vector<int>> &fruits;
// lower_bound 和 upper_bound 自定义<时参数不一样。
auto compare_fruit1 = [](vector<int> &a, int val){
return a[0] < val;
};
auto compare_fruit2 = [](int val, vector<int> &a){
return val < a[0];
};
int start_ge_min = lower_bound(fruits.begin(), fruits.end(), startPos, compare_fruit1) - fruits.begin();
int start_le_max = upper_bound(fruits.begin(), fruits.end(), startPos, compare_fruit2) - fruits.begin() - 1;
lower_bound/upper_bound实现¶
含义总结¶
- 递增序列(非递减)
- lower_bound,返回>= val 的最小索引
- upper_bound,返回>val 的最小索引
- 递减序列
- lower_bound,返回<= val 的最小索引
- upper_bound,返回<val 的最小索引 即:
- lower_bound,返回排序在 val 自身及右侧元素的最小索引
- upper_bound,返回排序在 val 右侧元素的最小索引
- 根据递增和递减,传入
<或>比较符号。不能传入含等于的比较符号,否则 lower_bound 和 upper_bound 含义互换。 - cmp 函数返回 true,表示前一个元素应该出现在后一个元素左侧。感觉没有什么情况是需要用到 cmp 包含等于情况的。
实现规律总结¶
- right 要更新永远都是更新为 mid
- left 根据反面情况更新为 mid+1
- 递增序列:
- lower_bound 反面情况为:mid < val,故
if (comp(*it,val)) - upper_bound 反面情况为:mid <= val, 故只用小于号表示为
if (!comp(val,*it))
- lower_bound 反面情况为:mid < val,故
- 递减序列:
- lower_boundf 反面情况为:mid > val,故
if (comp(*it,val)) - upper_bound 反面情况为:mid >= val,故只用大于号表示为`if (!comp(val,*it))
- lower_boundf 反面情况为:mid > val,故
- 递增序列:
- 返回的索引在
[0, n],当取到 n 时表示符合条件的没找到。
实现¶
感觉在 T 是基本类型,<号很明确的情况下,lower_bound 和 upper_bound 需要定义不同的函数就比较反直觉。
- 可以把 Compare 函数换成 get 函数,这样变成
get(\*it) < val
template <class ForwardIterator, class T>
ForwardIterator lower_bound (ForwardIterator first, ForwardIterator last, const T& val)
{
ForwardIterator it;
iterator_traits<ForwardIterator>::difference_type count, step;
count = distance(first,last);
while (count>0)
{
it = first; step=count/2; advance (it,step);
if (*it<val) { // or: if (comp(*it,val)), for version (2)
first=++it;
count-=step+1;
}
else count=step;
}
return first;
}
template <class ForwardIterator, class T>
ForwardIterator upper_bound (ForwardIterator first, ForwardIterator last, const T& val)
{
ForwardIterator it;
iterator_traits<ForwardIterator>::difference_type count, step;
count = std::distance(first,last);
while (count>0)
{
it = first; step=count/2; std::advance (it,step);
if (!(val<*it)) // or: if (!comp(val,*it)), for version (2)
{ first=++it; count-=step+1; }
else count=step;
}
return first;
}
动态规划¶
图解动态规划的解题四步骤(C++/Java/Python) - 打家劫舍 - 力扣(LeetCode)
- 定义子问题
- 写出子问题的递推关系
- 确定 DP 数组的计算顺序
- 空间优化(可选)
位运算¶
总结¶
分享|从集合论到位运算,常见位运算技巧分类总结! - 力扣(LeetCode)
(1<<n) - 1 //得到 n 位连续的 1
x & (-x) // 找出 x 的二进制表示中的最低位的 1 的位置,得到的值除该位外全 0
x & (x - 1) //将 x 最低位的 1 置为 0
- x & (-x) 原理在于-x 是补码,进行对 x 取反 +1 操作。二进制上,可以总结出变化规律:最低位 1 不变,左侧全部取反。因此与后,只有最低位 1 保持不变,其它全为 0.
Gosper's hack¶
void GospersHack(int k, int n)
{
int set = (1 << k) - 1;
int limit = (1 << n);
while (set < limit)
{
DoStuff(set);
// Gosper's hack:
int c = set & - set;
int r = set + c;
set = (((r ^ set) >> 2) / c) | r;
}
}
ProgrammingForInsomniacs: Gosper's Hack Explained
popcount¶
unsigned int popcount64(unsigned long long x)
{
x = (x & 0x5555555555555555ULL) + ((x >> 1) & 0x5555555555555555ULL);
x = (x & 0x3333333333333333ULL) + ((x >> 2) & 0x3333333333333333ULL);
x = (x & 0x0F0F0F0F0F0F0F0FULL) + ((x >> 4) & 0x0F0F0F0F0F0F0F0FULL);
return (x * 0x0101010101010101ULL) >> 56;
}
clz, ctz¶
计算头尾 0 的个数
- clz(count leading zero)
- ctz(count trailing zero)
https://stackoverflow.com/a/34687453
- x86 BSF(bit scan forward): least significant set bit (1 bit)
- x86 BSR(bit scan reverse):获得 most significant set bit (1 bit) index。注意,如果 src 为 0,则返回值未定义。
倍增¶
int getKthAncestor(int node, int k) {
int p = 0;
while(k){
if(k&1){
node = getAncestorPower2(node, p);
if(node==-1){
return -1;
}
}
p++;
k>>=1;
}
return node;
}
//https://leetcode.cn/problems/kth-ancestor-of-a-tree-node/solution/mo-ban-jiang-jie-shu-shang-bei-zeng-suan-v3rw/
int getKthAncestor(int node, int k) {
int m = 32 - __builtin_clz(k); // k 的二进制长度
for (int i = 0; i < m; i++) {
if ((k >> i) & 1) { // k 的二进制从低到高第 i 位是 1
node = pa[node][i];
if (node < 0) break;
}
}
return node;
}
// 另一种写法,不断去掉 k 的最低位的 1
int getKthAncestor2(int node, int k) {
for (; k && node != -1; k &= k - 1) // k & (k-1)
node = pa[node][__builtin_ctz(k)];
return node;
}
常用函数¶
编译器内置函数¶
位运算¶
GUN GCC 内置函数
__builtin_popcount = int
__builtin_popcountl = long int
__builtin_popcountll = long long
__builtin_clz # countl_zero
__builtin_ctz # countr_zero
__builtin_clzll
c++ 20 均变为标准函数
- leetcode 目前还无法使用
popcount
- countl_zero
- countr_zero
- countl_one
- countr_one
popcount( 00000000 ) = 0
popcount( 11111111 ) = 8
popcount( 00011101 ) = 4
countl_zero( 00000000 ) = 8
countl_zero( 11111111 ) = 0
countl_zero( 11110000 ) = 0
countl_zero( 00011110 ) = 3
countr_zero( 00000000 ) = 8
countr_zero( 11111111 ) = 0
countr_zero( 00011100 ) = 2
countr_zero( 00011101 ) = 0
lg¶
- bit_width = 1 + floor(log2(x)), 0 when x = 0
- floor(log2(x)) = bit_width - 1, max k, 2^k <= x
- int: bit_width = 32 - countl_zero(x)
c++20
黑魔法¶
各种高级数据结构¶
deque¶
和 vector 一样,支持随机访问。但是又可以在头部插入删除。为了实现这个特性,底层实现比较复杂。 cplusplus.com/reference/deque/deque/ 适用:
- 对于非常长的序列,reallocations 开销很大,因此比 vector 更适合。
SortedList/order statistic tree¶
- C++ tree find_by_order: C++ STL: Policy based data structures - Codeforces
- python sorted list: Sorted List — Sorted Containers 2.4.0 documentation (grantjenks.com)
使用 pb_ds 的 tree - 滑动子数组的美丽值 - 力扣(LeetCode) 模拟 - 滑动子数组的美丽值 - 力扣(LeetCode)
Order Statistic Tree – Morse (zheolong.github.io)
- Select(i) —— 查找树中的第_i_个最小元素;
- Rank(x) —— 查找元素_x_在树中的次序。
删除 heap 中指定元素:
- 方法一:维护一个 delete set,有点像 lazy remove
- 方法二:node based prior queue How to remove an arbitrary element from a standard heap in c++? - Stack Overflow
C/C++ error prone¶
IEEE754¶
表示
- sign: s
- significand: M
- exponet: E
位数
- float(32): 1 + 8 + 23
- double(64): 1 + 11 + 52
- extend(80), intel: 1 + 15 + 64
区间表示:
- normailized: exp 不全为 0 或 1
- 全 0

- 全 0